Vera Rubin & Feynman — The GPU Infrastructure That Will Redefine Enterprise Cloud
GB200 NVL72, 576 GPUs per rack, 1.5 exaflops FP4: Vera Rubin redefines enterprise GPU infrastructure. NVLink Fusion opens NVIDIA to AMD/Intel CPUs. Cloud vs on-prem TCO guide for solution architects.

Introduction — The Infrastructure That Changes Everything
At GTC 2026, Jensen Huang didn't just announce new GPUs. He redefined what it means to deploy AI in the enterprise. Vera Rubin and Feynman — two GPU architectures named after legendary physicists — represent a technological breakthrough that solution architects cannot ignore.
This B4 post in our GTC 2026 series takes a deep dive into these new architectures: what they change technically, why energy efficiency is reshaping cloud TCO, and how to position your infrastructure for the next decade of agentic AI.
1. Vera Rubin — The Rack-Scale Breakthrough
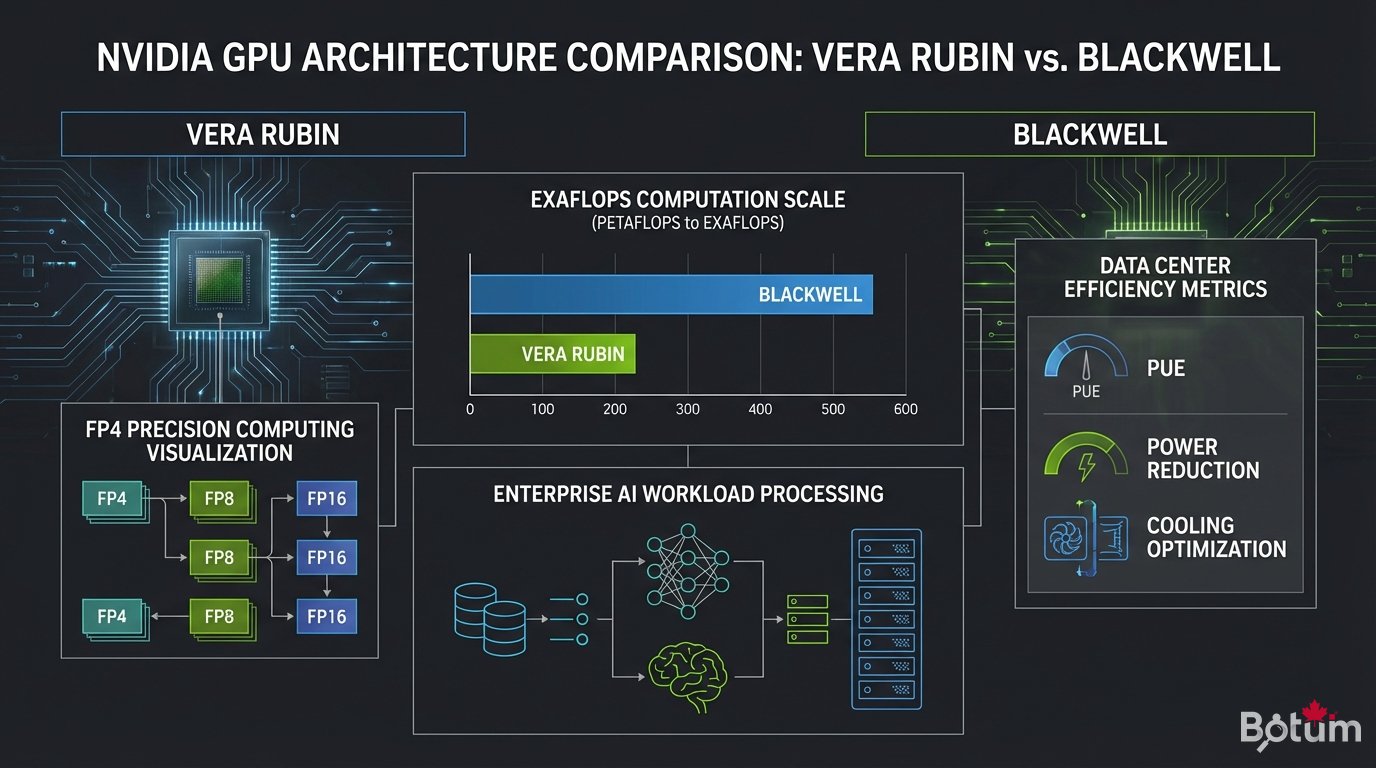
The GB200 NVL72 is the flagship product of the Vera Rubin architecture. To understand the magnitude of this leap, the numbers speak for themselves:
- 576 GPUs per rack — vs. 8-16 in a standard GPU server
- 1.5 exaflops FP4 per rack — the power of a national supercomputer in a single bay
- 6th-gen NVLink — 3.6 TB/s bandwidth between rack GPUs
- 4x better energy efficiency vs. the Hopper generation (H100)
Vera Rubin's true innovation isn't raw power — it's the rack-scale computing approach. The 576 GPUs in a NVL72 operate as a single giant processor, connected via NVLink at speeds equivalent to a traditional CPU's internal memory. There are no longer boundaries between GPUs; the AI model sees them as a single massive compute unit.
A single Vera Rubin NVL72 rack can run GPT-4 real-time inference for 10,000 simultaneous users. Keep that figure handy for your next TCO calculation.
2. Vera Rubin Ultra — The June 2026 Configuration
NVIDIA didn't wait to push the architecture further. Vera Rubin Ultra, announced for June 2026, doubles down:
- 2x GB300 — the Pro version of the Vera Rubin GPU with massive HBM4
- 3 exaflops FP4 per rack — double the standard configuration
- Unified HBM4 memory — no more bottleneck on 100B+ parameter models
- Optimized TDP — despite doubled performance, power consumption stays controlled
For enterprises planning on-premise deployments, the strategic window is clear: Q1-Q2 2026 for standard Vera Rubin, mid-2026 for Vera Rubin Ultra. The investment decision needs to be made now.
3. NVLink Fusion — The Strategic Opening
One of the most significant announcements at GTC 2026 for enterprise architects: NVLink Fusion. For the first time, NVIDIA opens its NVLink interconnect to third-party CPUs:
- AMD EPYC — your existing AMD servers connect directly to Vera Rubin GPUs
- Intel Xeon — same, with no extra abstraction layer
- Arm Neoverse — ideal for cloud-native and edge computing deployments
What this changes in practice: you no longer need to replace your entire CPU infrastructure to access NVIDIA GPU power. Investment is targeted at what matters — AI compute power — without replacing functional, amortized servers.
NVLink Fusion transforms Vera Rubin from an "all-NVIDIA" product into an open infrastructure compatible with your existing assets. It's the interoperability signal the enterprise ecosystem was waiting for.
4. Feynman — The 2028 Vision
Jensen Huang also unveiled Feynman, Blackwell's successor scheduled for 2028. Few technical details were shared, but the strategic implications are significant:
- Deliberate early announcement: NVIDIA signals its 2-year roadmap to allow enterprises to plan their investment cycles
- Blackwell successor: Feynman will continue the GPU line for large-scale inference and training
- Implication for architects: investing in Vera Rubin today doesn't lock you in — you're on the NVIDIA roadmap
NVIDIA's innovation cadence is now one year between major generations. This is no longer Moore's Law — it's Jensen's Law. Enterprise architectures must integrate this velocity into their planning cycle.
5. Implications for Enterprise Solution Architects
Cloud vs. On-Premise — The New TCO Calculation
With Vera Rubin, the financial equation has changed. Here's how to recalibrate your TCO:
- Cloud GPU (current H100): ~$3/hr per GPU H100, ~$26K/year for continuous use
- Vera Rubin NVL72 on-prem: a rack at ~$3M amortized over 5 years = $600K/year for 576 GPUs — 5-10x cheaper per FLOP at high utilization
- Typical break-even: 18-24 months from 40% continuous utilization
The rule of thumb: if your GPU utilization exceeds 40% continuously and you can handle the operational overhead, on-prem Vera Rubin is financially justifiable from rack-scale deployment.
HPC to Agentic AI Migration
Many enterprises have existing HPC clusters (simulation, rendering, financial analysis). Vera Rubin is the natural gateway to agentic AI:
- CUDA stays compatible — your HPC workloads run without modification
- NVLink Fusion preserves your AMD/Intel CPU investments
- Dual use: HPC by day, AI training by night
Quick Decision Guide
- If <100 GPUs → hyperscaler cloud (AWS, Azure, GCP) remains optimal
- If 100-1000 GPUs → evaluate dedicated HPC cloud (CoreWeave, Lambda Labs) or Vera Rubin on-prem for sensitive data
- If >1000 GPUs → Vera Rubin NVL72 on-prem or colo, NVLink Fusion for existing CPU integration
- Ultra-sensitive data → on-prem only, GDPR/SOC2/HIPAA compliance by design
📥 COMPLETE GUIDE — GTC 2026 · Post B4
⬇ Download the guide (PDF)🚀 Go Further with BOTUM
This guide covers the fundamentals. In production, every GPU infrastructure decision has its specifics — TCO, compliance, migration. BOTUM teams help organizations evaluate and implement their enterprise GPU strategy. Let's talk.
Discuss your project →