Vera Rubin & Feynman — L'infrastructure GPU qui va redéfinir le cloud enterprise
GB200 NVL72, 576 GPU par rack, 1,5 exaflops FP4 : Vera Rubin redéfinit l'infrastructure GPU enterprise. NVLink Fusion ouvre NVIDIA aux CPU AMD/Intel. Guide TCO cloud vs on-prem pour les architectes solutions.

Introduction — L'infrastructure qui change la donne
Au GTC 2026, Jensen Huang n'a pas seulement annoncé de nouveaux GPU. Il a redéfini ce que signifie déployer de l'IA en entreprise. Vera Rubin et Feynman — deux architectures GPU qui portent les noms de physiciens légendaires — représentent une rupture technologique que les architectes solutions ne peuvent pas ignorer.
Ce billet B4 de notre série GTC 2026 analyse en profondeur ces nouvelles architectures : ce qu'elles changent techniquement, pourquoi l'efficacité énergétique redessine le TCO cloud, et comment positionner votre infrastructure pour la prochaine décennie d'IA agentique.
1. Vera Rubin — La rupture rack-scale
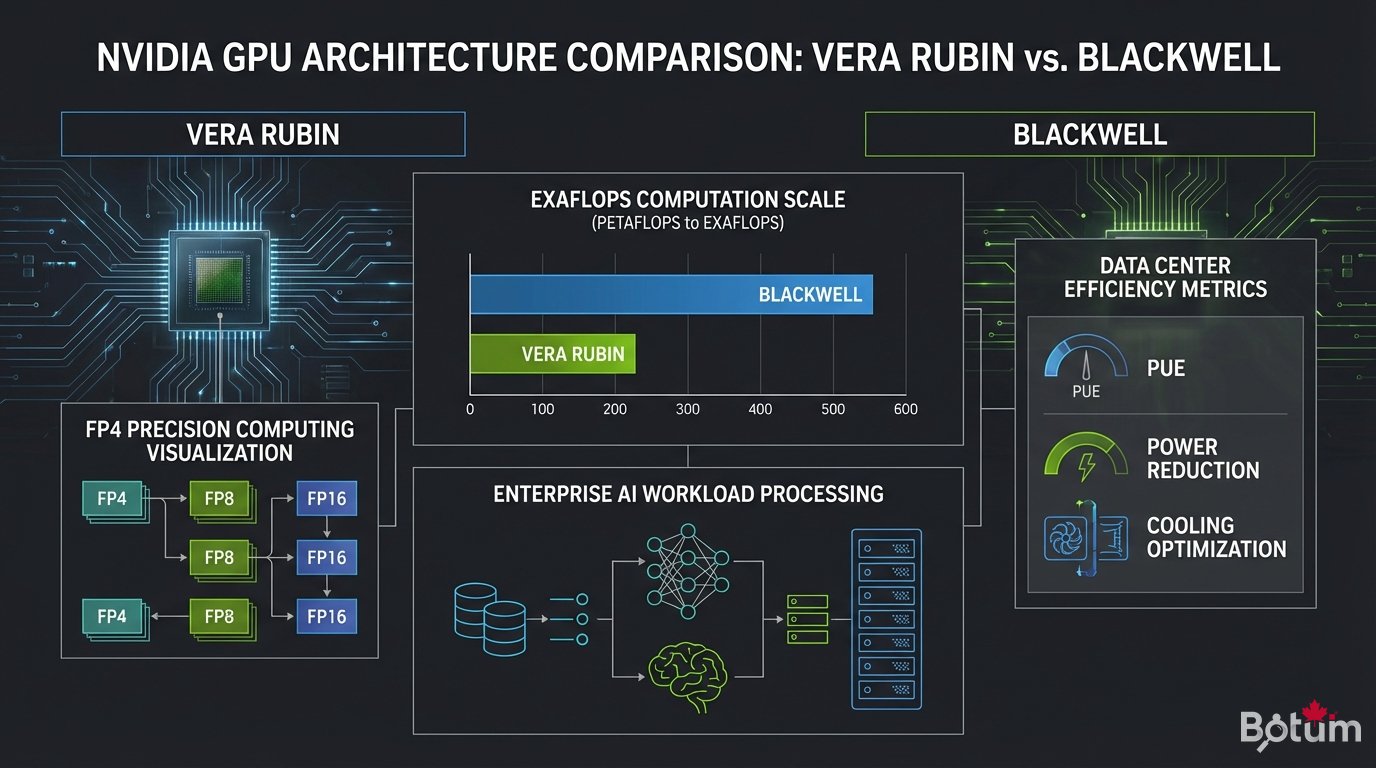
Le GB200 NVL72 est le produit phare de l'architecture Vera Rubin. Pour comprendre l'ampleur du saut technologique, les chiffres parlent d'eux-mêmes :
- 576 GPU par rack — contre 8 à 16 dans un serveur GPU classique
- 1,5 exaflops FP4 par rack — la puissance d'un supercalculateur national dans une seule baie
- NVLink 6e génération — bande passante 3,6 TB/s entre les GPU du rack
- Efficacité énergétique 4x meilleure que la génération Hopper (H100)
La vraie innovation de Vera Rubin n'est pas la puissance brute — c'est l'approche rack-scale computing. Les 576 GPU d'un NVL72 fonctionnent comme un seul processeur géant, connectés via NVLink à des vitesses équivalentes à la mémoire interne d'un CPU traditionnel. Il n'y a plus de frontière entre les GPU ; le modèle IA les voit comme une seule unité de calcul massive.
Un seul rack Vera Rubin NVL72 peut faire tourner GPT-4 en inférence temps réel pour 10 000 utilisateurs simultanés. Ce chiffre est à retenir pour votre prochain calcul TCO.
2. Vera Rubin Ultra — La configuration juin 2026
NVIDIA n'a pas attendu pour pousser l'architecture encore plus loin. Vera Rubin Ultra, annoncé pour juin 2026, double la mise :
- 2x GB300 — la version Pro du GPU Vera Rubin avec HBM4 massif
- 3 exaflops FP4 par rack — le double de la configuration standard
- Mémoire HBM4 unifiée — plus de goulot d'étranglement sur les modèles 100B+ paramètres
- TDP optimisé — malgré la puissance doublée, consommation électrique maîtrisée
Pour les entreprises qui planifient des déploiements on-premise, la fenêtre stratégique est claire : Q1-Q2 2026 pour Vera Rubin standard, mi-2026 pour Vera Rubin Ultra. La décision d'investissement doit se prendre maintenant.
3. NVLink Fusion — L'ouverture stratégique
L'une des annonces les plus significatives du GTC 2026 pour les architectes enterprise : NVLink Fusion. Pour la première fois, NVIDIA ouvre son interconnexion NVLink aux CPU de tiers :
- AMD EPYC — vos serveurs AMD existants se connectent directement aux GPU Vera Rubin
- Intel Xeon — idem, sans couche d'abstraction supplémentaire
- Arm Neoverse — parfait pour les déploiements cloud natif et edge computing
Ce que ça change concrètement : vous n'avez plus à remplacer toute votre infrastructure CPU pour accéder à la puissance GPU NVIDIA. L'investissement est ciblé sur ce qui compte — la puissance de calcul AI — sans remplacer des serveurs fonctionnels et amortis.
NVLink Fusion transforme Vera Rubin d'un produit "tout NVIDIA" en une infrastructure ouverte compatible avec votre parc existant. C'est un signal d'interopérabilité fort que l'écosystème enterprise attendait.
4. Feynman — La vision 2028
Jensen Huang a aussi levé le voile sur Feynman, le successeur de Blackwell prévu pour 2028. Peu de détails techniques ont été partagés, mais les implications stratégiques sont importantes :
- Annonce précoce délibérée : NVIDIA signale sa feuille de route sur 2 ans pour permettre aux entreprises de planifier leurs cycles d'investissement
- Successeur de Blackwell : Feynman continuera la ligne GPU pour l'inférence et le training à grande échelle
- Implication pour les architectes : investir en Vera Rubin aujourd'hui ne vous met pas en cul-de-sac — vous êtes sur la feuille de route NVIDIA
La cadence d'innovation NVIDIA est désormais d'un an entre générations majeures. Ce n'est plus la "loi de Moore" — c'est la "loi de Jensen". Les architectures d'entreprise doivent intégrer cette vélocité dans leur cycle de planification.
5. Implications pour les architectes solutions enterprise
Cloud vs On-Premise — Le nouveau calcul TCO
Avec Vera Rubin, l'équation financière a changé. Voici comment recalibrer votre TCO :
- Cloud GPU (H100 actuel) : ~$3/heure par GPU H100, soit ~$26 000/an pour usage continu
- Vera Rubin NVL72 on-prem : un rack ~$3M amortissable sur 5 ans = $600K/an pour 576 GPU — soit 5 à 10x moins cher par FLOP à usage élevé
- Break-even typique : 18 à 24 mois à partir de 40% d'utilisation continue
La règle empirique : si votre utilisation GPU dépasse 40% en continu et que vous pouvez gérer l'opérationnel, l'on-prem Vera Rubin est justifiable financièrement dès le déploiement à l'échelle rack.
Migration HPC vers IA agentique
Beaucoup d'entreprises disposent de clusters HPC existants (simulation, rendu, analyses financières). Vera Rubin est la passerelle naturelle vers l'IA agentique :
- CUDA reste compatible — vos workloads HPC tournent sans modification
- NVLink Fusion préserve vos investissements CPU AMD/Intel
- Double usage : HPC le jour, entraînement IA la nuit
Guide de décision rapide
- Si <100 GPU → cloud hyperscaler (AWS, Azure, GCP) reste optimal
- Si 100-1000 GPU → évaluer HPC cloud dédié (CoreWeave, Lambda Labs) ou Vera Rubin on-prem si données sensibles
- Si >1000 GPU → Vera Rubin NVL72 on-prem ou collo, NVLink Fusion pour intégration CPU existante
- Si données ultra-sensibles → on-prem uniquement, conformité RGPD/SOC2/HIPAA par design
📥 GUIDE COMPLET — GTC 2026 · Billet B4
⬇ Télécharger le guide (PDF)🚀 Aller plus loin avec BOTUM
Ce guide couvre les fondamentaux. En production, chaque décision d'infrastructure GPU a ses spécificités — TCO, conformité, migration. Les équipes BOTUM accompagnent les organisations dans l'évaluation et l'implémentation de leur stratégie GPU enterprise. Parlons-en.
Discuter de votre projet →