Mémoire et contexte dans OpenClaw : MEMORY.md, compactions et long-terme à l'échelle
L'IA n'a pas de mémoire native — mais un agent opérationnel en a besoin. BOTUM documente son architecture de mémoire : MEMORY.md, daily notes, compactions et gestion à l'échelle d'un réseau de 15 agents en production.

Toute l'intelligence d'un agent opérationnel tient dans sa capacité à se souvenir. Pas d'une session à l'autre de façon native — mais d'une architecture délibérée, construite et maintenue par les équipes qui déploient ces systèmes.
Le paradoxe fondamental de l'IA agentique : les modèles de langage n'ont pas de mémoire persistante. Chaque session commence de zéro, comme si l'agent venait d'être allumé pour la première fois. Et pourtant, un agent opérationnel — qui gère des emails, pilote des automatisations, prend des décisions au nom d'une organisation — ne peut pas fonctionner sans continuité. BOTUM a résolu ce paradoxe. Voici comment.
1. Fenêtre de contexte vs mémoire persistante
La confusion la plus fréquente chez les équipes qui débutent avec les agents IA : confondre la fenêtre de contexte avec la mémoire. Ce sont deux choses fondamentalement différentes.
La fenêtre de contexte est la quantité d'information qu'un modèle peut traiter en une seule session. Claude Sonnet gère environ 200 000 tokens. En apparence généreux — en pratique, insuffisant pour une organisation qui fait tourner des agents depuis 6 mois. Cette fenêtre est volatile : elle s'efface à la fin de chaque session. Elle sature aussi : quand un agent accumule des logs, des fichiers, des instructions et des conversations, la fenêtre se remplit vite, et les informations les plus anciennes "tombent" — disparaissent silencieusement du contexte actif.
La mémoire persistante, c'est ce qui reste entre les sessions. C'est un artefact de votre infrastructure, pas du modèle. Elle ne se crée pas seule : quelqu'un — ou quelque chose — doit décider quoi écrire, où, et quand.
Ce que l'on perd quand on ne gère pas la mémoire : les décisions prises les semaines précédentes, les préférences exprimées, les erreurs déjà documentées, les contextes clients. Ce qui disparaît dans la fenêtre de contexte est perdu à jamais si ça n'a pas été écrit quelque part.
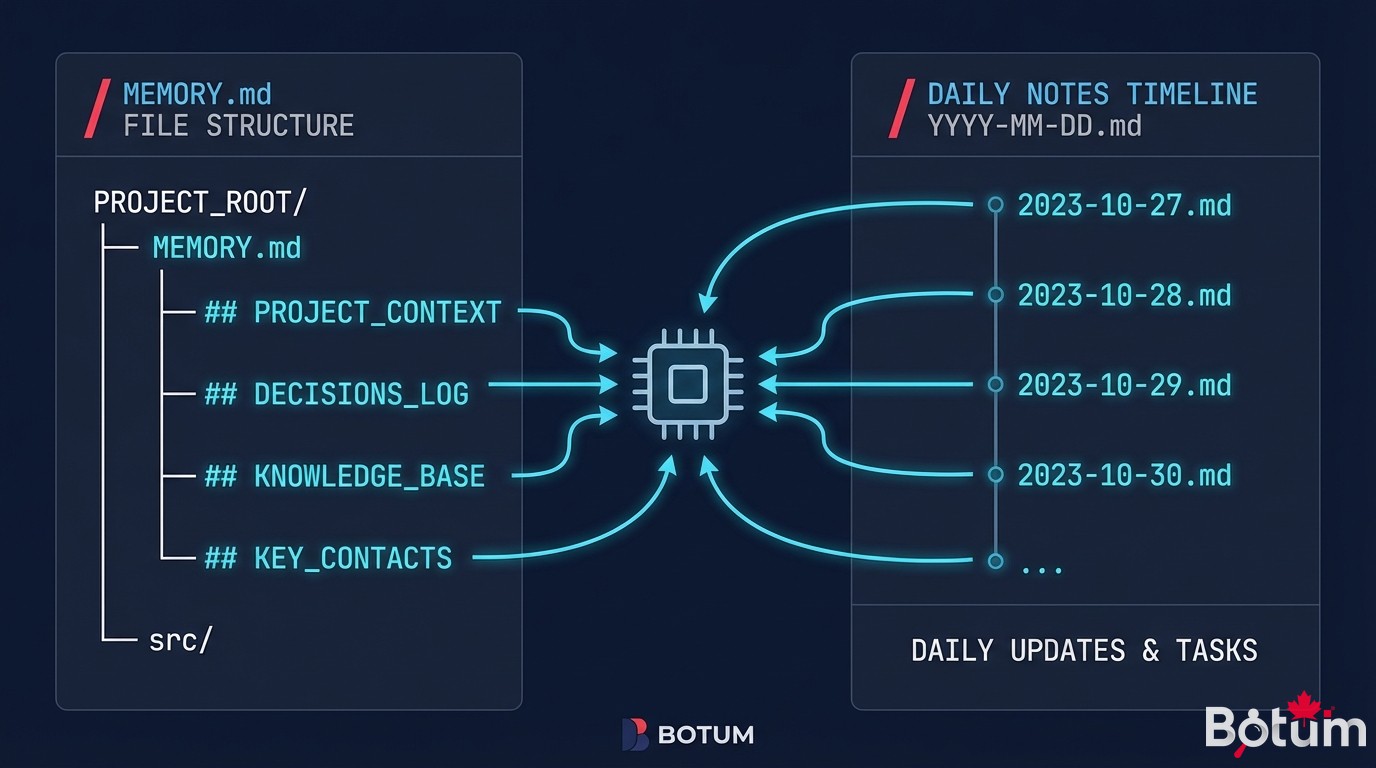
2. MEMORY.md — la mémoire long-terme
Dans l'architecture OpenClaw, MEMORY.md est le fichier de mémoire consolidée. Il contient ce qui doit persister au-delà des sessions individuelles : les règles permanentes, les faits importants sur l'organisation et ses acteurs, les décisions structurelles, les préférences établies.
Ce qu'on y met :
- Les règles immuables de l'agent (jamais CC cette adresse, toujours formater ainsi, etc.)
- Les informations clés sur l'organisation (équipes, interlocuteurs, processus récurrents)
- Les décisions importantes et leur rationale
- Les erreurs documentées à ne plus répéter
- Les intégrations et leurs particularités (tel webhook a ce comportement, tel service répond lentement)
Ce qu'on n'y met pas : les logs d'événements bruts, les résultats de requêtes ponctuelles, les conversations du jour. Ces éléments appartiennent aux daily notes.
Règles de curation BOTUM pour MEMORY.md :
- Taille maîtrisée : viser 2 000 à 5 000 tokens maximum. Au-delà, le fichier est lui-même un problème de contexte.
- Sections stables : organiser par domaine (organisation, agents, règles, intégrations). Chaque section a une taille plafond.
- Principe d'écriture active : ne rien ajouter sans décider simultanément ce que ça remplace ou ce qu'on peut supprimer.
- Versioning Git : chaque modification de
MEMORY.mdest un commit. L'historique permet de retrouver une règle supprimée par erreur.
Ce fichier est lu au début de chaque session principale. C'est l'injection de contexte qui permet à l'agent de "se souvenir" — même si le modèle sous-jacent ne se souvient de rien.
3. Les daily notes — les logs bruts quotidiens
Les daily notes (memory/YYYY-MM-DD.md) sont les journaux de bord de l'agent. Chaque jour a son fichier. On y capture en temps réel ce qui se passe : actions effectuées, décisions prises, événements notables, erreurs rencontrées.
Quand écrire dans les daily notes :
- Après chaque action significative (email envoyé, script exécuté, configuration modifiée)
- Quand une règle implicite a été appliquée (pour la rendre explicite)
- Quand un comportement inattendu a été observé (pour investigation ultérieure)
- Quand une décision a été prise qui pourrait être questionnée plus tard
Ce qu'on capture :
- Le quoi (action précise), le pourquoi (contexte), le résultat
- Les heuristiques utilisées pour trancher une ambiguïté
- Les références (numéro de ticket, identifiant client, URL concernée)
- Les signaux d'alerte qui méritent attention (mais ne justifient pas encore une action)
Les daily notes ne sont pas écrites pour être lues en session courante — elles sont l'archive qui permet la compaction et la recherche ultérieure. Leur valeur n'est pas immédiate : elle est dans l'accumulation.
4. Les compactions — distiller la mémoire
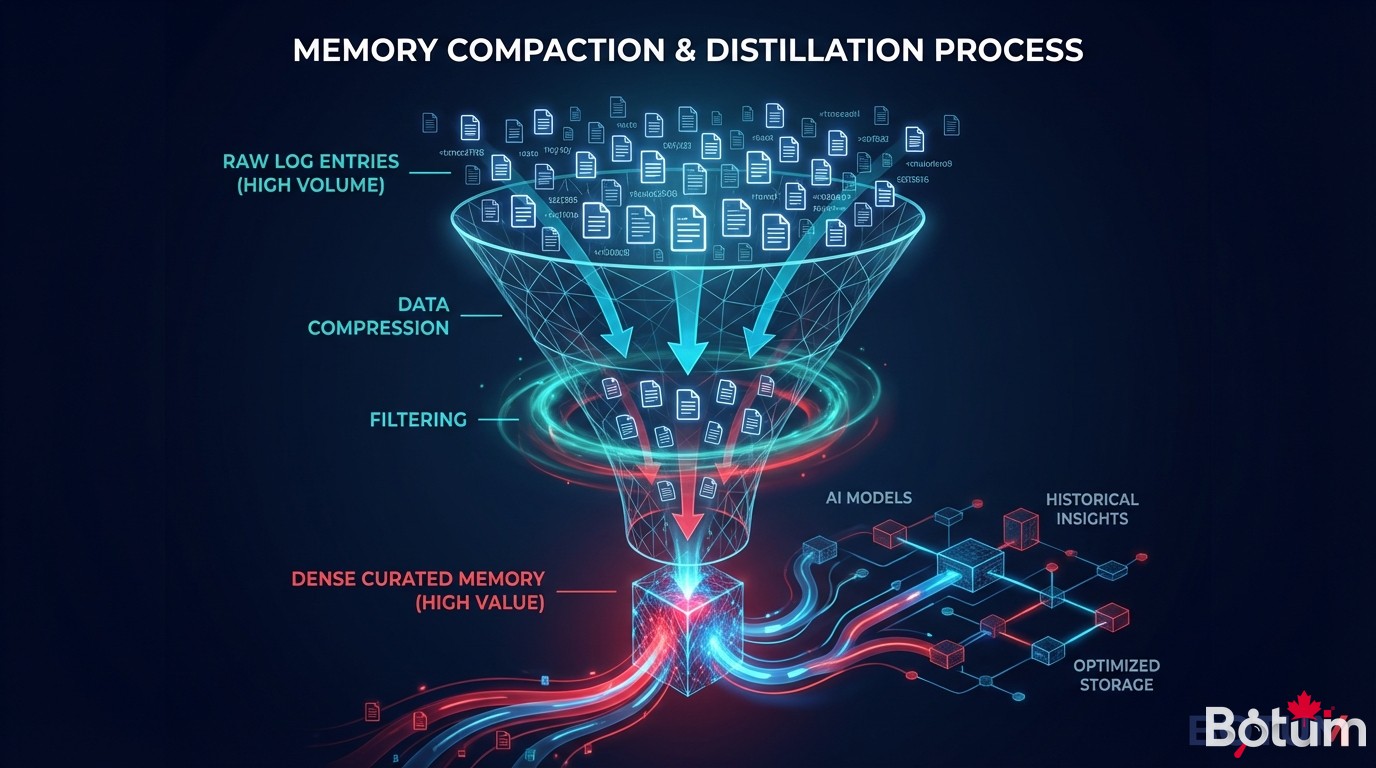
La compaction est l'opération de distillation : on prend un volume de daily notes et on en extrait ce qui mérite de survivre dans MEMORY.md. C'est la tâche la plus délicate de la gestion de mémoire agent.
Quand compacter :
- Quand la fenêtre de contexte approche de la saturation (indicateur : >40% d'utilisation en session standard)
- Périodiquement, indépendamment de l'utilisation (hebdomadaire ou mensuel selon le volume)
- Avant d'aborder un nouveau domaine ou un nouveau projet
- Quand
MEMORY.mddevient lui-même trop lourd
Comment décider quoi garder :
- Test de permanence : cette information sera-t-elle encore pertinente dans 3 mois ?
- Test de fréquence : cet élément sera-t-il consulté souvent, ou c'est un événement unique ?
- Test de dérivabilité : peut-on retrouver cette info ailleurs (Git, fichiers sources) si nécessaire ?
- Test de règle : cet événement révèle-t-il une règle générale applicable à d'autres situations ?
Ce qu'on perd irrémédiablement lors d'une compaction : la granularité. La richesse des détails dans une daily note ne survit pas à la distillation. On garde l'essence — la règle, la décision, le fait clé. On perd le contexte qui entourait cet élément. C'est un sacrifice délibéré et nécessaire.
BOTUM a formalisé un protocole de compaction en 4 étapes :
- Relecture des daily notes de la période
- Extraction des candidats à la persistance (règles, décisions, erreurs documentées)
- Mise à jour de
MEMORY.mdavec fusion et déduplication - Commit Git avec message descriptif — les daily notes restent dans l'archive, non supprimées
5. Mémoire partagée vs mémoire isolée
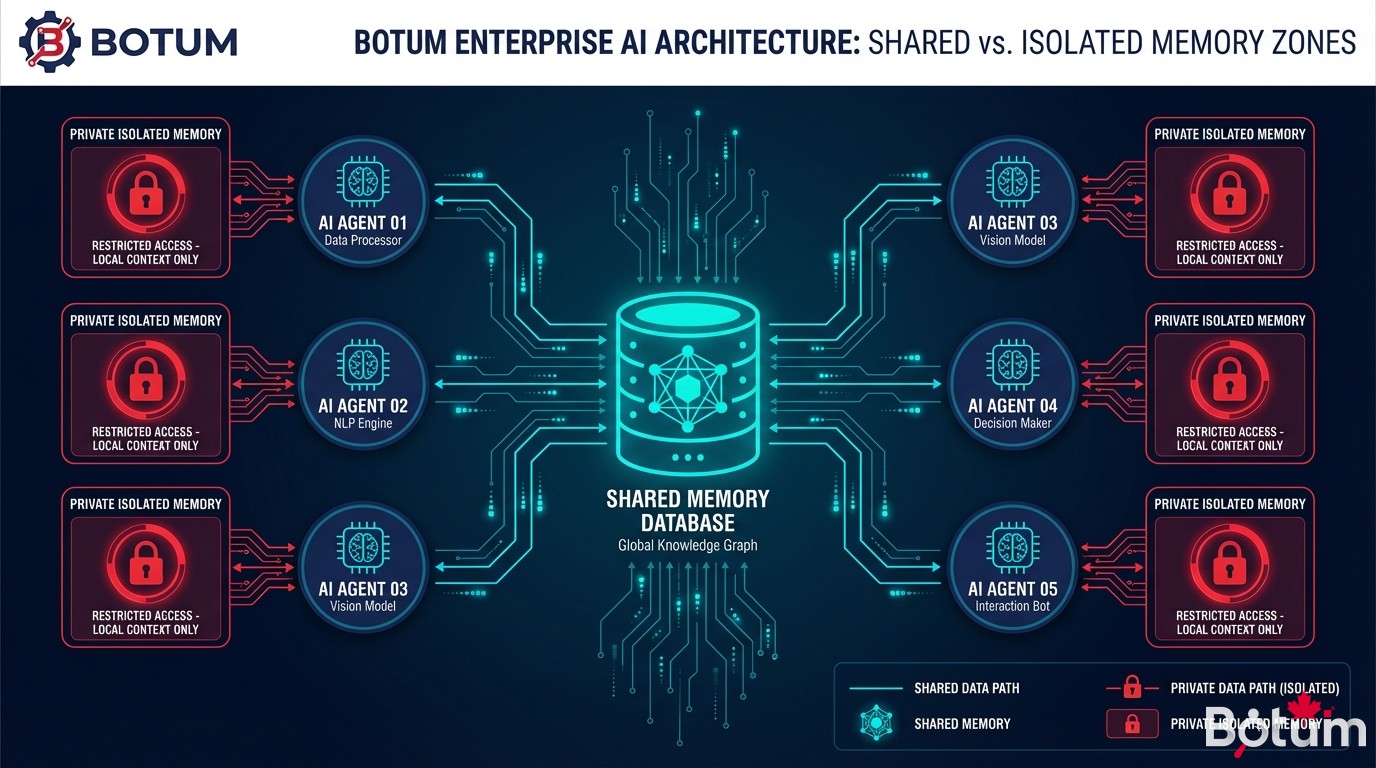
Dans un réseau multi-agents, la question de la mémoire prend une dimension supplémentaire : quelle information est partagée entre agents, et quelle information reste privée à un agent ?
Mémoire partagée : le workspace commun. Les fichiers dans le répertoire racine du workspace — MEMORY.md, CODEX.md, AGENTS.md — sont accessibles à tous les agents. C'est la mémoire organisationnelle : les règles communes, l'état du système, les décisions collectives.
Mémoire isolée : les répertoires d'agents. Chaque agent peut avoir son propre répertoire (agents/nom-agent/) avec ses notes privées, ses configurations spécifiques, ses contextes d'exécution. Ce qui reste dans ce répertoire n'est pas injecté automatiquement dans les autres agents.
Le principe de séparation chez BOTUM :
- Les règles qui s'appliquent à tous → workspace partagé (
MEMORY.md) - Les règles spécifiques à un domaine → répertoire de l'agent concerné
- Les logs d'exécution → daily notes de l'agent concerné, pas dans le workspace commun
- Les artefacts inter-agents (fichiers à passer d'un agent à l'autre) → répertoire dédié (
handoffs/)
La tentation est de tout mettre dans le workspace partagé pour "que tout soit visible". C'est une erreur. Un workspace partagé qui grossit sans contrôle devient rapidement une source de bruit — et finit par nuire à la qualité de contexte de tous les agents.
6. Recherche sémantique en mémoire
Les daily notes s'accumulent. Après 6 mois de production, un réseau de 15 agents peut générer plusieurs milliers de fichiers. Comment retrouver une décision prise il y a 3 mois dans les notes d'un agent ?
Deux niveaux de recherche sont disponibles dans OpenClaw :
Recherche textuelle : grep -r "mot-clé" memory/ ou équivalent. Efficace pour retrouver des occurrences exactes ou des identifiants connus (numéro de client, nom d'un service).
Recherche sémantique : via des requêtes langage naturel sur les daily notes. L'agent lit les fichiers les plus pertinents et synthétise. Cette approche consomme des tokens — elle est réservée aux recherches importantes où la précision prime sur le coût.
Pratiques BOTUM pour garder les notes recherchables :
- Toujours inclure des identifiants explicites dans les notes (noms propres, identifiants système, URLs)
- Structurer les entrées avec des en-têtes cohérents (
## Décision,## Erreur,## Règle) - Maintenir un index sommaire mensuel : une page qui liste les décisions clés du mois, avec dates
- Pour les décisions critiques : dupliquer dans
MEMORY.mdavec une référence vers la daily note source
7. À l'échelle : 15 agents, 6 mois de mémoire
À mesure que le réseau grandit, la mémoire devient un enjeu d'infrastructure. Voici les défis concrets que BOTUM a rencontrés :
Volume : 15 agents générant chacun des daily notes pendant 6 mois représente potentiellement 2 700 fichiers (si 1 fichier/agent/jour). En pratique, certains agents sont plus actifs que d'autres — mais le volume dépasse rapidement la capacité de supervision humaine directe.
Dégradation de la qualité : sans entretien actif, MEMORY.md accumule des règles obsolètes, des informations contradictoires, des références à des projets terminés. La mémoire qui "grossit" sans curation finit par nuire autant qu'aider.
Incohérences inter-agents : quand plusieurs agents mettent à jour le workspace partagé, les conflits Git et les incohérences logiques apparaissent. Un agent peut documenter une règle dans MEMORY.md qui contredit une règle ajoutée par un autre agent la semaine précédente.
Protocoles BOTUM à cette échelle :
- Agent système dédié à la mémoire : un agent (JARVIS) est responsable de l'entretien du workspace. Il audite
MEMORY.mdhebdomadairement, déclenche les compactions, résout les conflits. - Règles de contribution : seul l'agent système peut modifier
MEMORY.mddirectement. Les autres agents soumettent des "propositions de mémoire" dans un fichier staging que JARVIS traite. - Archivage des daily notes : après 90 jours, les daily notes sont archivées hors du workspace actif mais restent accessibles. La recherche sur les archives est explicitement différenciée de la recherche sur les notes récentes.
- Monitoring de la taille : un cron journalier mesure la taille des fichiers clés et alerte si
MEMORY.mddépasse un seuil.
8. Anti-patterns à éviter
Les équipes qui débutent avec la mémoire agent reproduisent les mêmes erreurs. En voici trois fondamentales :
Anti-pattern 1 : Tout mettre dans MEMORY.md. La tentation naturelle est de centraliser. Mais un MEMORY.md de 20 000 tokens est un problème de contexte permanent — il prend de la place dans chaque session, il est difficile à maintenir, et il dilue la pertinence des informations importantes dans un volume de bruit.
Anti-pattern 2 : Ne jamais compacter. Les daily notes s'accumulent indéfiniment. Sans compaction périodique, l'archive grossit, les recherches deviennent coûteuses, et la mémoire long-terme reste prisonnière de la granularité brute des logs. La compaction n'est pas optionnelle — c'est un processus de maintenance obligatoire.
Anti-pattern 3 : Confondre contexte et mémoire. Le contexte actif (ce qui est dans la fenêtre de la session en cours) n'est pas de la mémoire. Injecter massivement des fichiers dans le contexte ne remplace pas une architecture de mémoire bien conçue — et surcharge la fenêtre de tokens inutilement.
🚀 Aller plus loin avec BOTUM
La gestion de la mémoire agent est l'un des sujets les plus sous-estimés — et les plus critiques — dans les déploiements IA enterprise. Les équipes BOTUM ont développé des protocoles de mémoire qui survivent à 6 mois de production et à des dizaines de milliers d'échanges. Si vous voulez bâtir quelque chose qui dure, parlons-en.
Discuter de votre projet →📄 Télécharger ce guide en PDF
Version complète : protocoles de mémoire, checklist de compaction, anti-patterns documentés.
Télécharger le PDF →Conclusion
La mémoire agent n'est pas une fonctionnalité — c'est une infrastructure. Elle se conçoit, se déploie, se maintient. Elle dégrade si on ne l'entretient pas. Elle scale si on anticipe ses contraintes.
L'architecture MEMORY.md + daily notes + compactions périodiques n'est pas la seule réponse au problème — mais c'est celle que BOTUM a validée en production sur 6 mois et plus de 50 000 échanges d'agents. Elle est simple à comprendre, robuste à l'usage, et compatible avec les contraintes réelles des équipes IT enterprise.
→ Billet 10 à venir : OpenClaw et les bases de données — comment brancher des agents sur PostgreSQL, SQLite et des APIs structurées pour aller au-delà de la mémoire fichier.

