OpenClaw + DeepSeek : LLM local, open-source et réduction des coûts API
Un réseau de 15 agents OpenClaw = plusieurs millions de tokens/mois. BOTUM documente sa stratégie hybride : DeepSeek local via Ollama pour les tâches mécaniques, cloud premium pour le complexe. Calcul de ROI réel, limites terrain, et conclusion de la série.

Un réseau de 15 agents IA actifs, c'est facilement 5 à 10 millions de tokens par mois envoyés au cloud. À 15 $/million de tokens (Claude Sonnet, GPT-4), la facture dépasse rapidement les 100 $/mois — pour des tâches qui, pour la majorité d'entre elles, ne nécessitent pas le meilleur modèle du marché. La question n'est plus "cloud ou local ?" mais "comment router intelligemment ?"
Ce billet clôt notre série de 7 sur le déploiement OpenClaw chez BOTUM. On l'a voulu plus exhaustif que les précédents : DeepSeek + Ollama + routing hybride + calcul de ROI réel. C'est le billet qu'on aurait voulu lire avant de commencer.
1. Le problème de coût à l'échelle
Quand on déploie un ou deux agents en OpenClaw, le coût API cloud reste marginal. Mais à mesure que le réseau grossit — agents système, email, calendrier, rédaction, facturation, veille, infra — le volume de tokens explose.
Chez BOTUM, voici une estimation réelle de notre réseau à 15 agents :
- Agents à haute fréquence (système, email, monitoring) : ~300 000 tokens/jour chacun
- Agents à fréquence moyenne (rédaction, calendrier, facturation) : ~100 000 tokens/jour
- Agents ponctuels (veille, infra, recrutement) : ~50 000 tokens/session
Total estimé : 6 à 8 millions de tokens/mois. À ~15 $/M tokens (Claude Sonnet 4), ça représente 90 à 120 $/mois — soit plus de 1 000 $/an juste en tokens API pour des tâches souvent mécaniques.
La solution : ne pas envoyer toutes ces tâches au modèle le plus cher. C'est là qu'intervient DeepSeek.
2. Pourquoi DeepSeek ?
DeepSeek a surpris le marché en 2024-2025 avec des performances comparables à GPT-4 sur de nombreux benchmarks — pour un modèle open-source, déployable en local, et gratuitement. Ce n'est pas une promesse marketing : les résultats sur MMLU, HumanEval et GSM8K placent DeepSeek-V3 et DeepSeek-R1 parmi les meilleurs modèles disponibles.
Points forts pour un usage OpenClaw :
- Open-source et gratuit — aucune licence, déployable sur votre infra sans frais récurrents
- Performances solides sur les tâches structurées — résumés, classification, extraction, génération de code utilitaire
- Compatible Ollama — intégration native, une ligne de config pour l'activer dans OpenClaw
- Contexte long disponible — DeepSeek-V3 supporte jusqu'à 128K tokens de contexte
- Modèles de tailles variées — du 7B (CPU-friendly) au 67B (GPU optimisé)
Où il excelle : tâches répétitives bien définies, résumés d'emails, classification de tickets, génération de rapports structurés, monitoring et alertes, scripts utilitaires.
Où il est moins fort : raisonnement complexe multi-étapes, nuances culturelles fines (traduction littéraire, copywriting subtil), instructions très longues avec contraintes imbriquées.
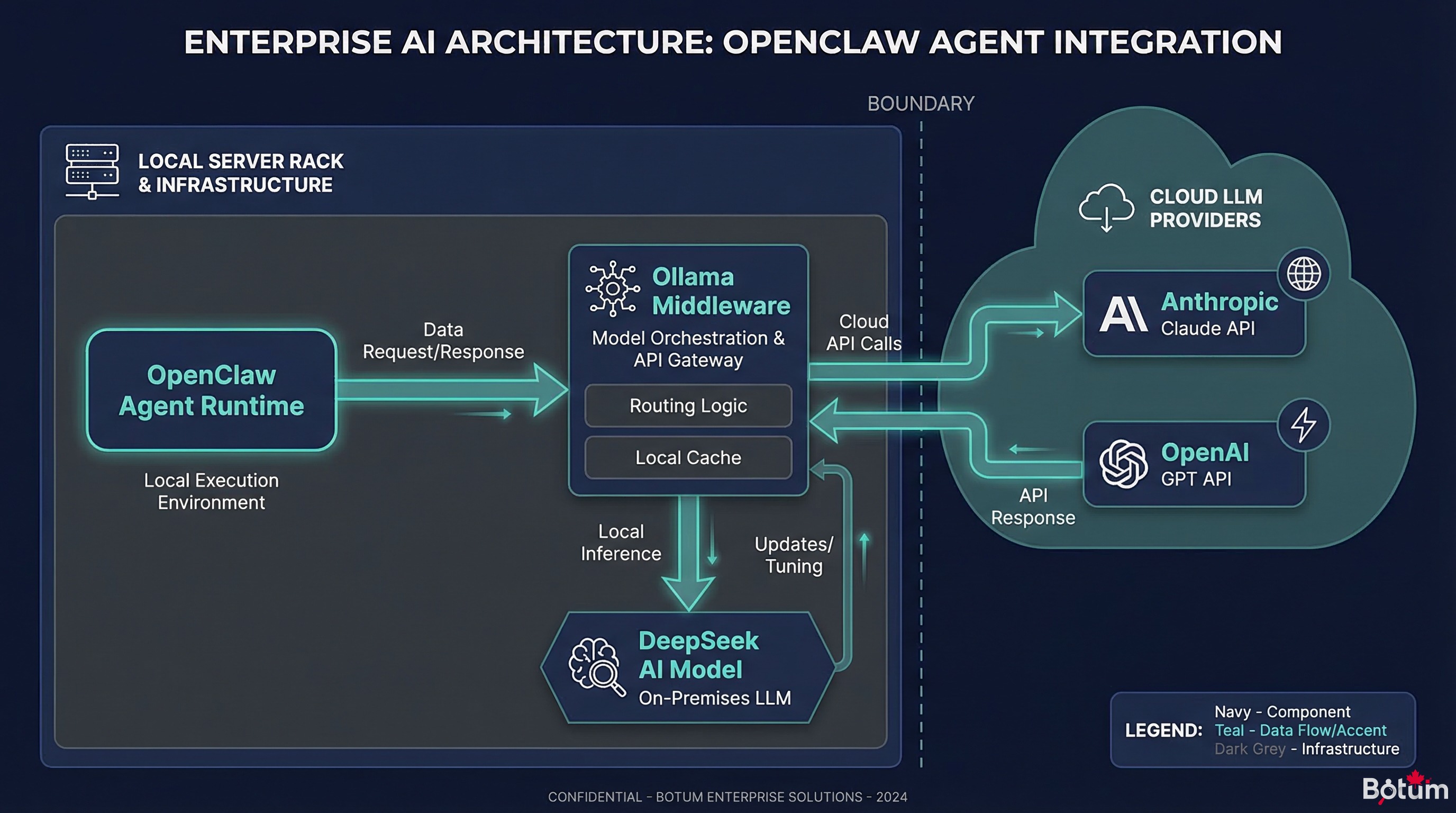
3. Architecture : OpenClaw + DeepSeek via Ollama
La connexion entre OpenClaw et un modèle local se fait via Ollama, qui expose une API compatible OpenAI. La configuration est simple.
Étape 1 — Installer Ollama
curl -fsSL https://ollama.ai/install.sh | sh
ollama pull deepseek-v3
# Pour la version compacte (moins de RAM requise) :
ollama pull deepseek-r1:7bÉtape 2 — Configurer OpenClaw
Dans ~/.openclaw/openclaw.json, ajouter un provider Ollama :
{
"providers": {
"ollama-local": {
"type": "openai-compatible",
"baseUrl": "http://localhost:11434/v1",
"model": "deepseek-v3",
"apiKey": "ollama"
}
}
}Étape 3 — Assigner le modèle à des agents spécifiques
Dans la config de l'agent (ex. agent système) :
{
"agent": "jarvis",
"model": "ollama-local",
"fallback_model": "anthropic/claude-sonnet-4-6"
}Latence et ressources
| Configuration | RAM requise | Latence (réponse ~500 tokens) | Usages recommandés |
|---|---|---|---|
| DeepSeek 7B — CPU seul | 8 Go RAM | 15-30 secondes | Tâches non urgentes, batch overnight |
| DeepSeek 7B — GPU (RTX 3060) | 8 Go VRAM | 2-4 secondes | Tâches courantes, agents fréquents |
| DeepSeek 67B — GPU (A100) | 40+ Go VRAM | 5-10 secondes | Tâches complexes, qualité proche cloud |
| Claude Sonnet (cloud) | — | 1-3 secondes | Tâches complexes, production critique |
Constat terrain : Sans GPU dédié, DeepSeek en CPU est trop lent pour des agents à haute fréquence. Avec un GPU modeste (RTX 3060 ou équivalent), la latence devient acceptable pour la majorité des tâches mécaniques.
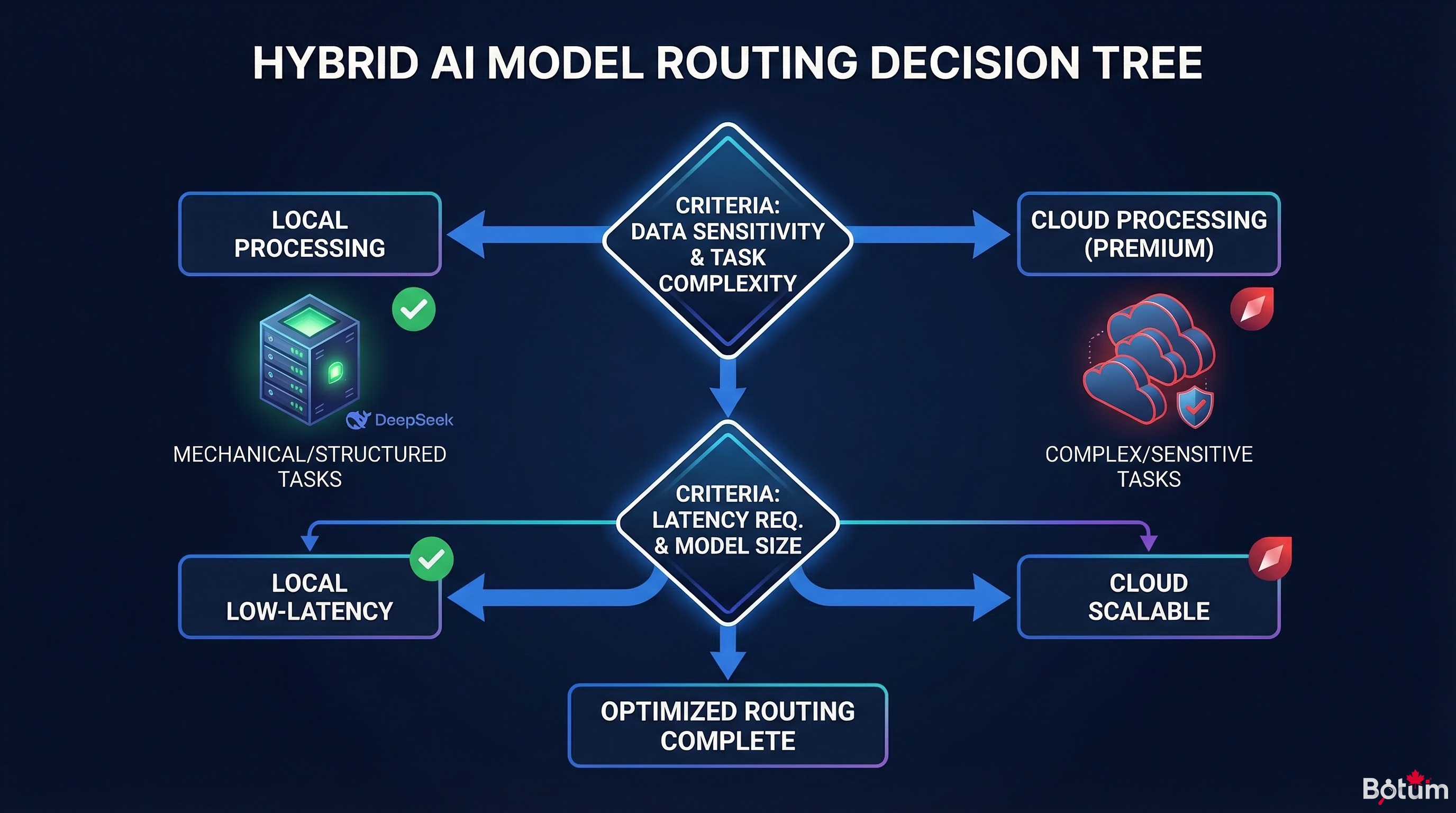
4. Stratégie de routing hybride
Le vrai levier d'optimisation n'est pas de remplacer le cloud par le local — c'est de router chaque tâche vers le modèle le plus adapté.
La logique de décision en 5 questions
- Est-ce une tâche structurée et bien définie ? (classification, résumé court, extraction de champs) → Local (DeepSeek)
- Est-ce une tâche interactive avec l'utilisateur ? (réponse directe en chat, email client) → Cloud léger (Haiku, GPT-3.5)
- Est-ce une tâche de raisonnement complexe ? (analyse stratégique, debugging, architecture) → Cloud puissant (Claude Sonnet/Opus, GPT-4)
- La vitesse de réponse est-elle critique ? (<2 secondes attendues) → Cloud (latence plus prévisible)
- Y a-t-il des données sensibles ? → Local obligatoire
Implémentation dans OpenClaw
OpenClaw permet de définir le modèle par agent et par type de tâche. Voici le pattern qu'on utilise :
# Agents haute fréquence / tâches mécaniques → DeepSeek local
agents_local = ["jarvis", "aegis", "chronos-digest", "argus-veille"]
# Agents interactifs / qualité importante → Claude Haiku
agents_haiku = ["hermes", "nexus", "forge"]
# Tâches complexes / rédaction / analyse → Claude Sonnet
agents_premium = ["cyrano", "career", "knox-audit"]En pratique, on configure un fallback automatique : si le modèle local n'est pas disponible (redémarrage, saturation GPU), l'agent bascule automatiquement vers le cloud. Continuité garantie.
5. Économies réelles — Calcul de ROI
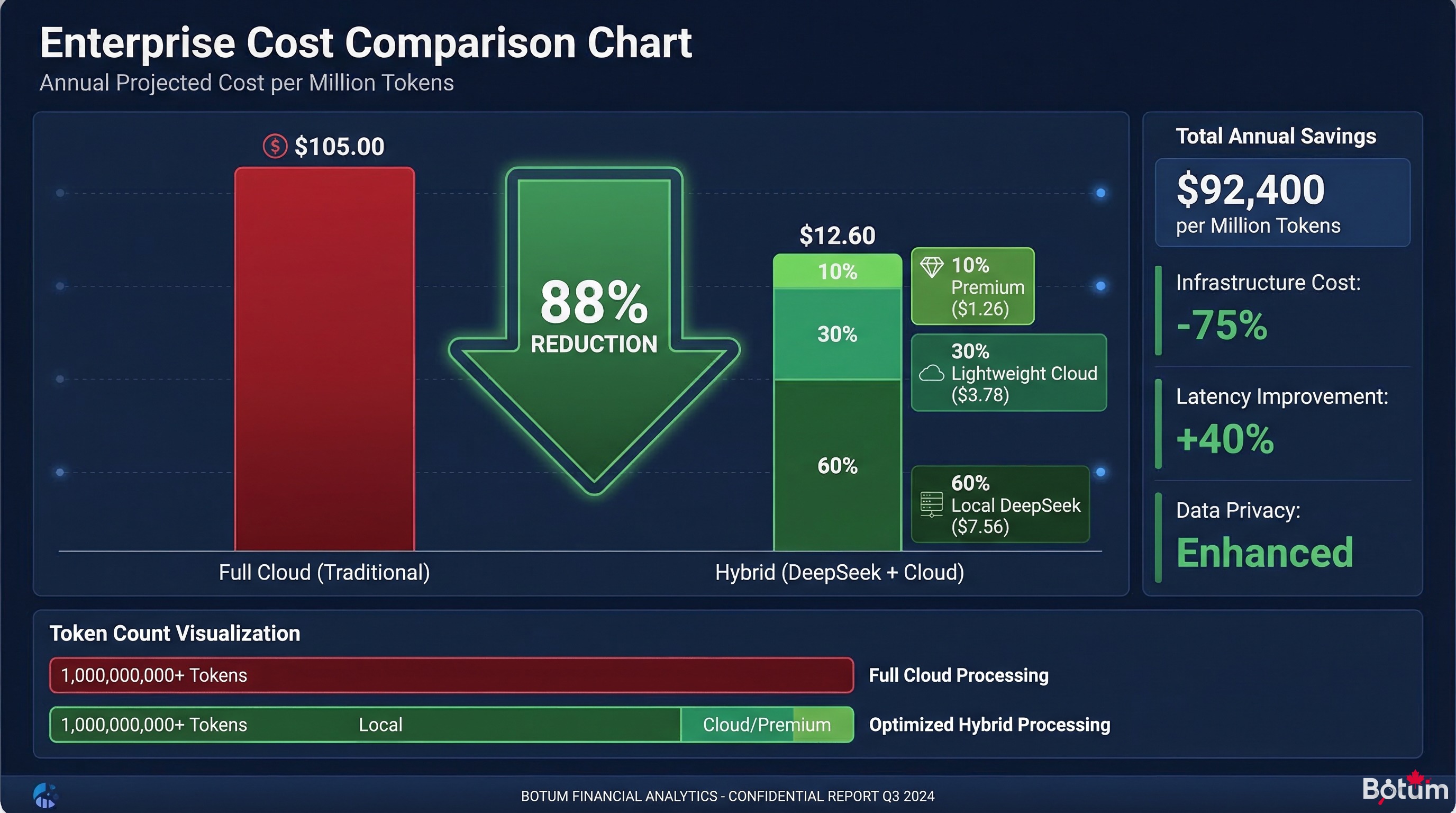
Scénario de base — réseau 15 agents, sans optimisation
| Modèle | Tokens/mois | Coût/M tokens | Coût/mois |
|---|---|---|---|
| Claude Sonnet 4 (tout en cloud) | 7 000 000 | 15 $ | 105 $ |
Scénario optimisé — routing hybride (60% local, 30% cloud léger, 10% cloud premium)
| Modèle | Tokens/mois | Coût/M tokens | Coût/mois |
|---|---|---|---|
| DeepSeek local (Ollama) | 4 200 000 | ~0 $* | ~0 $ |
| Claude Haiku (cloud léger) | 2 100 000 | 1 $ | 2,10 $ |
| Claude Sonnet (cloud premium) | 700 000 | 15 $ | 10,50 $ |
| TOTAL OPTIMISÉ | 7 000 000 | — | ~12,60 $ |
* Coût électricité estimé à ~3-5 $/mois pour un GPU RTX 3060 en usage partiel.
Économie mensuelle : ~92 $ → ~88 % de réduction. Seuil de rentabilité de l'investissement GPU (RTX 3060 ≈ 450 $ d'occasion) : environ 5 mois.
6. Limites à connaître
Un retour terrain honnête inclut les limites. Voici ce qu'on a découvert en production :
Latence et disponibilité du GPU
Le GPU est une ressource partagée. Si plusieurs agents déclenchent des appels simultanés, les requêtes se mettent en file d'attente. Pour un réseau de 15 agents actifs, un seul GPU peut créer des goulots d'étranglement aux heures de pointe (typiquement 8h-10h et 14h-16h).
Mitigation : fallback automatique vers le cloud en cas de saturation, ou second GPU dédié aux agents haute fréquence.
Qualité variable selon les tâches
DeepSeek 7B est nettement inférieur à Claude Sonnet sur les tâches qui requièrent du jugement nuancé : copywriting fin, emails à haute valeur commerciale, analyses stratégiques complexes. On a appris (parfois à nos dépens) à ne pas confier ces tâches au modèle local.
Règle pratique : si le résultat de la tâche va être lu par un humain extérieur à l'équipe, utiliser le cloud premium par défaut.
Contexte long : attention aux fenêtres
DeepSeek-V3 supporte 128K tokens en théorie. En pratique, la qualité des réponses se dégrade significativement au-delà de 32K tokens sur les modèles locaux de taille moyenne. Pour les analyses de gros volumes de documents, le cloud reste plus fiable.
Maintenance de l'infra locale
Un modèle local, c'est de l'infrastructure à maintenir : mises à jour Ollama, gestion des drivers GPU, espace disque (les modèles pèsent 4 à 40 Go), monitoring de santé. Ce coût de maintenance est réel — à intégrer dans le calcul de ROI total.
Cas où le cloud reste indispensable
- Tâches en temps réel (<1 seconde de latence requise)
- Raisonnement très complexe (Agent réflexif, planification multi-étapes)
- Contextes très longs (>50K tokens effectifs)
- Accès aux web search, tools avancés, vision (multimodal)
- Pendant les maintenances de l'infra locale
7. Retour terrain BOTUM
Après plusieurs mois de déploiement hybride, voici ce qu'on utilise réellement chez BOTUM :
Ce qu'on fait aujourd'hui
- DeepSeek 7B (Ollama, GPU RTX) : agents JARVIS (système), AEGIS (monitoring), ARGUS (veille RSS), heartbeats automatiques
- Claude Haiku : agent HERMÈS (digests email), CHRONOS (rappels calendrier), NEXUS (LinkedIn simple)
- Claude Sonnet 4 : agent CYRANO (rédaction), KNOX (sécurité), analyses complexes, sessions interactives avec Faiçal
Ce qu'on ferait différemment
- Commencer par le routing d'emblée — on a fait tourner tout en cloud pendant 2 mois avant d'optimiser. Coût inutile.
- Dimensionner le GPU avant de déployer — le CPU-only est trop lent pour un réseau actif. Avec le recul, le GPU est un prérequis, pas une option.
- Tester DeepSeek sur chaque type de tâche avant de l'assigner — on a découvert ses limites sur le copywriting de façon embarrassante. Un benchmark rapide évite les surprises.
- Mettre en place le fallback automatique dès le jour 1 — pas après le premier incident de disponibilité à 2h du matin.

8. Conclusion de série — Ce qu'on a construit en 7 billets
On a commencé cette série avec une question simple : un réseau d'agents IA self-hosted, est-ce vraiment utile en entreprise — ou est-ce de la complexité pour la complexité ?
Après 7 billets et plusieurs mois de production, la réponse est claire : oui, c'est utile — mais à condition d'y aller méthodiquement.
Voici ce que cette série aura couvert :
- B1 : Le concept — OpenClaw comme runtime d'agents, pas comme chatbot
- B2 : L'installation — workspace, skills, premier agent opérationnel
- B3 : La sécurité — SSL, reverse proxy, vault, authentification robuste
- B4 : Les secrets — gestion des credentials et contexte IA
- B5 : Les agents — JARVIS, HERMÈS, CHRONOS et la logique de spécialisation
- B6 : Le comparatif — OpenClaw vs ChatGPT vs Claude API, honnêtement
- B7 (ce billet) : L'optimisation des coûts — DeepSeek, Ollama, routing hybride
Ce qu'on n'a pas dit dans cette série (par respect pour votre attention) : les détails d'implémentation qui dépendent de votre environnement spécifique, les arbitrages qui n'ont pas de bonne réponse universelle, les configurations qui ont mis des semaines à stabiliser. C'est là que l'expertise terrain fait la différence.
Si vous lisez cette série en envisageant de déployer OpenClaw : faites-le. Commencez petit (un agent, un cas d'usage concret), validez la valeur, puis étendez. La courbe d'apprentissage est réelle mais gérable. Et les gains opérationnels, une fois le réseau rodé, justifient largement l'investissement.
🚀 Prêt à déployer OpenClaw dans votre organisation ?
Cette série de 7 billets couvre les fondamentaux. Mais passer de la théorie à un réseau d'agents en production dans votre environnement, c'est une autre histoire.
Les équipes BOTUM accompagnent les organisations dans le déploiement d'architectures IA enterprise — de l'audit de vos besoins jusqu'à la mise en production. Chaque projet est différent. Le vôtre aussi.
Parler à un expert BOTUM →Téléchargez ce guide en PDF pour le consulter hors ligne.
Télécharger le guide (PDF)Toute la série OpenClaw
- B1 — OpenClaw : de l'assistant IA au réseau d'agents
- B2 — Installation et premier agent opérationnel
- B3 — Sécuriser OpenClaw : SSL, reverse proxy, vault
- B4 — Secrets, credentials et contexte IA
- B5 — Configurer les premiers agents : JARVIS, HERMÈS, CHRONOS
- B6 — OpenClaw vs ChatGPT vs Claude API : comparatif honnête
- B7 — OpenClaw + DeepSeek : LLM local et réduction des coûts (ce billet)
🚀 Aller plus loin avec BOTUM
Ce guide couvre les bases. En production, chaque environnement a ses spécificités. Les équipes BOTUM accompagnent les organisations dans le déploiement, la configuration avancée et la sécurisation de leur infrastructure. Si vous avez un projet, parlons-en.
Discuter de votre projet →
