OpenClaw + bases de données : PostgreSQL, RAG et recherche sémantique
La série technique OpenClaw se clôt sur l'intégration base de données : PostgreSQL via psycopg2, pipeline RAG avec pgvector, et recherche sémantique sur vos données internes. Architecture concrète, checklist terrain.
Les fichiers plats ont leur utilité. Mais quand un réseau d'agents doit lire, écrire et raisonner sur des données structurées à l'échelle — les bases de données changent la donne. Ce billet clôt la série technique OpenClaw sur une note concrète : PostgreSQL, RAG et recherche sémantique dans un déploiement agent IA.
1. Au-delà des fichiers : pourquoi connecter OpenClaw à une vraie base de données
Un agent OpenClaw peut lire et écrire des fichiers Markdown, JSON, CSV. Pour beaucoup d'usages, c'est suffisant. Le workspace Git comme système de persistance couvre 80 % des scénarios d'automatisation courante : logs, notes, configurations, états inter-sessions.
Mais certaines situations nécessitent plus :
- Volumes importants — un historique de 50 000 transactions ne se lit pas raisonnablement en Markdown.
- Requêtes dynamiques — filtrer les clients par revenu, par date, par statut : SQL est le bon outil, pas grep.
- Concurrence — plusieurs agents qui écrivent simultanément dans le même fichier créent des race conditions. Une base de données gère ça nativement.
- Recherche sémantique — retrouver des documents par sens, pas par mot-clé exact : ça nécessite un vector store, pas un fichier texte.
Selon une étude Gartner 2025, 61 % des déploiements d'agents IA en production ont besoin d'une couche de persistance structurée dans les 6 premiers mois d'opération. L'intégration base de données n'est pas une option avancée — c'est la prochaine étape naturelle.
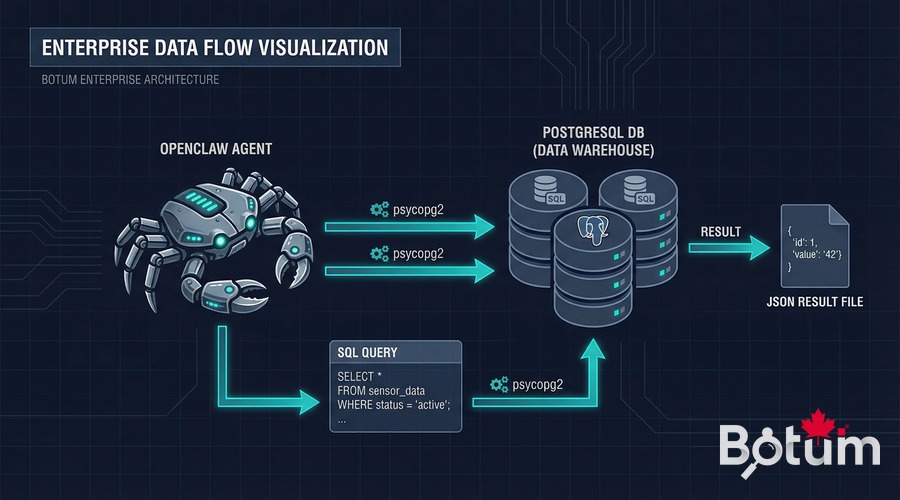
2. PostgreSQL + OpenClaw : connexion directe via scripts
L'intégration la plus directe : un script Python dans le workspace de l'agent. L'agent exécute le script via son skill exec, le script se connecte à PostgreSQL via psycopg2, effectue les opérations, retourne les résultats dans un fichier JSON que l'agent lit ensuite.
Architecture typique :
Agent → exec(scripts/query_db.py --action timesheet --user BOTUM)
↓
scripts/query_db.py → psycopg2 → PostgreSQL
↓
data/query-result.json → Agent lit → traite → répondExemple de connexion dans un script agent :
import psycopg2, json, os
conn = psycopg2.connect(
host=os.environ['PG_HOST'],
dbname=os.environ['PG_DB'],
user=os.environ['PG_USER'],
password=os.environ['PG_PASS']
)
cur = conn.cursor()
cur.execute(
"SELECT client, SUM(hours) as total "
"FROM timesheets WHERE month=%s "
"GROUP BY client ORDER BY total DESC",
('2026-03',))
results = [{'client': r[0], 'hours': float(r[1])} for r in cur.fetchall()]
with open('data/timesheet-result.json', 'w') as f:
json.dump(results, f, ensure_ascii=False, indent=2)
conn.close()
print(f"Résultats écrits : {len(results)} clients")Règle de sécurité absolue : les credentials PostgreSQL ne sont jamais dans le workspace Git. Ils transitent via des variables d'environnement injectées par le vault au démarrage de l'agent — le même principe que pour tout credential dans OpenClaw (voir Billet 4 de cette série).
3. Cas d'usage concrets
Timesheet automatique
L'agent LEDGER de BOTUM exécute chaque vendredi un script qui agrège les entrées timesheet depuis PostgreSQL, génère un rapport Markdown, et l'envoie en digest. Le résultat : aucune intervention humaine pour les rapports hebdomadaires.
CRM mis à jour par un agent
Après chaque appel client loggé dans la messagerie, l'agent NEXUS extrait les informations clés (décision prise, prochaine étape, persona de contact) et insère/met à jour la ligne correspondante dans la table contacts de PostgreSQL. Le CRM se tient à jour en temps réel, sans saisie manuelle.
Logs structurés d'opérations
Chaque action significative des agents (email envoyé, rapport généré, alerte déclenchée) est loggée dans une table agent_logs avec horodatage, agent source, type d'action et statut. Cela permet un audit complet et des tableaux de bord opérationnels — impossible à faire de façon fiable avec des fichiers texte.
4. RAG (Retrieval-Augmented Generation) : pourquoi ça change tout
Un LLM a une fenêtre de contexte limitée. Vous ne pouvez pas lui injecter 10 000 pages de documentation, l'historique complet d'un CRM, ou 5 ans de décisions techniques. Le RAG résout ce problème.
Le principe : plutôt que d'injecter tout le contenu dans le prompt, on récupère seulement les passages les plus pertinents à la question posée, et on les injecte. La pertinence est calculée non pas par correspondance exacte de mots-clés, mais par similarité sémantique — proximité de sens dans l'espace vectoriel.
Architecture simple d'un pipeline RAG :
1. Indexation (une fois)
Documents → Embeddings (vecteurs 1536 dims) → Stockage (pgvector ou fichier)
2. Requête (chaque question)
Question → Embedding → Recherche similarité → Top-K passages → Contexte LLM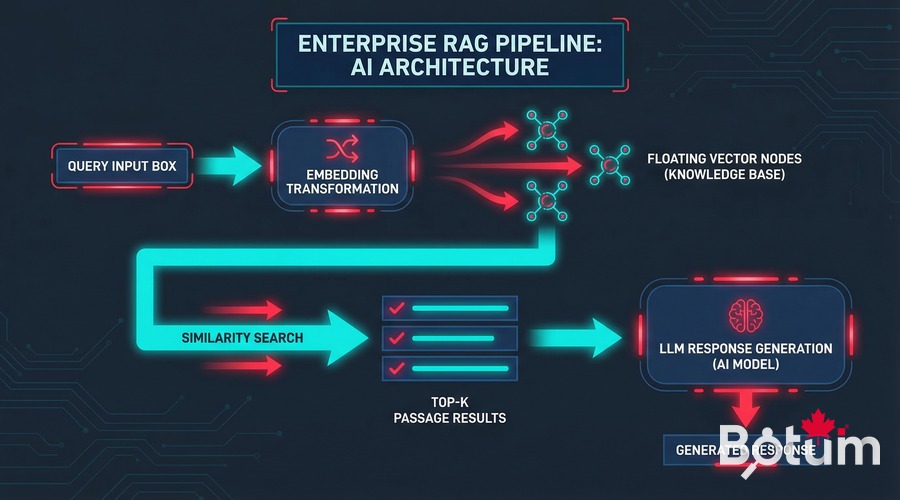
5. Implémenter un RAG basique avec OpenClaw
Étape 1 : Générer des embeddings
Un embedding est une représentation vectorielle dense d'un texte — un tableau de 1536 nombres qui capture le "sens" du texte. Des textes sémantiquement proches ont des vecteurs proches dans cet espace.
import openai, json, numpy as np
client = openai.OpenAI()
def get_embedding(text: str) -> list[float]:
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
# Indexer des documents
documents = [
{"id": "doc1", "content": "Décision architecturale : PostgreSQL pour le CRM..."},
{"id": "doc2", "content": "Réunion du 12 mars : migration prévue pour Q3..."},
]
for doc in documents:
doc["embedding"] = get_embedding(doc["content"])
# Sauvegarder (approche simple : fichier JSON)
with open("data/embeddings.json", "w") as f:
json.dump(documents, f)Étape 2 : pgvector pour le stockage vectoriel (recommandé en production)
Pour les petits volumes (< 10 000 documents), un fichier JSON et une recherche cosinus en Python suffisent. Pour la production, l'extension pgvector de PostgreSQL est la solution naturelle si vous êtes déjà sur Postgres.
-- Installation pgvector
CREATE EXTENSION IF NOT EXISTS vector;
-- Table de documents
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
source VARCHAR(200),
embedding vector(1536)
);
-- Index pour recherche rapide (HNSW recommandé)
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops);
-- Requête de similarité
SELECT content, source,
1 - (embedding <=> %s::vector) AS similarity
FROM documents
ORDER BY embedding <=> %s::vector
LIMIT 5;Étape 3 : Pipeline complet dans un script agent
def rag_query(question: str, top_k: int = 5) -> str:
# Retourne le contexte pertinent pour une question.
q_embedding = get_embedding(question)
# Recherche dans pgvector
cur.execute(
"SELECT content, source, "
"1-(embedding <=> %s::vector) AS score "
"FROM documents "
"ORDER BY embedding <=> %s::vector LIMIT %s",
(q_embedding, q_embedding, top_k))
passages = cur.fetchall()
context = "
---
".join([
f"Source: {p[1]} (score: {p[2]:.2f})
{p[0]}"
for p in passages if p[2] > 0.7 # seuil de pertinence
])
return context6. Recherche sémantique sur vos données
La recherche sémantique est la conséquence immédiate d'un pipeline RAG opérationnel. Au lieu de chercher "PostgreSQL" dans vos notes, vous cherchez "décisions d'architecture base de données" — et vous retrouvez les passages pertinents même s'ils ne contiennent pas le mot exact.
Cas d'usage concrets chez BOTUM :
- Retrouver des décisions passées — "Quelle était la décision sur l'architecture de backup ?" → l'agent retrouve le passage exact dans les notes de réunion, même de 8 mois auparavant.
- Trouver les billets similaires — avant de publier un billet, vérifier si on a déjà couvert ce sujet sous un autre angle. La recherche sémantique évite les doublons que la recherche par mots-clés rate.
- Chercher dans un CRM — "Quels clients ont mentionné des problèmes de sécurité ?" → scan sémantique des notes de contacts, pas une recherche exacte.
- Knowledge base interne — les agents retrouvent la procédure standard applicable à une situation, même formulée différemment.
7. Limites et réalité terrain
Le RAG n'est pas une baguette magique. Les équipes BOTUM ont identifié plusieurs limites concrètes :
Qualité des embeddings
Un mauvais texte d'entrée produit un mauvais embedding. Si vos notes de réunion sont des bullet points cryptiques ("Migration — décision finale — voir Slack"), l'embedding ne capture pas grand chose. La qualité du corpus d'indexation détermine la qualité des résultats.
Coût des embeddings
Avec text-embedding-3-small (OpenAI), le coût est de $0.02 pour 1 million de tokens. Pour un corpus de 10 000 documents de 500 tokens chacun : ~$0.10 pour l'indexation initiale. Raisonnable — mais ça s'accumule si on réindexe trop souvent.
Latence
Un pipeline RAG ajoute 200-500ms à chaque requête (appel API embedding + recherche vectorielle). Pour un agent interactif, c'est souvent invisible. Pour un pipeline batch de 1 000 requêtes, ça compte.
Quand le RAG est inutile
Si vos données tiennent en moins de 50 000 tokens (environ 150 pages), injectez-les directement dans le contexte. Claude 3.5 Sonnet gère 200 000 tokens de contexte. Le RAG introduit une complexité qui n'est pas toujours justifiée.
8. Architecture recommandée : quand utiliser quoi
| Situation | Solution recommandée | Pourquoi |
|---|---|---|
| Données < 50K tokens, statiques | Injection directe dans contexte | Zéro latence, zéro complexité |
| Données structurées, requêtes filtrées | PostgreSQL direct via psycopg2 | SQL > grep, concurrence gérée |
| < 10K docs, proto/dev | JSON + cosinus en Python | Simple, pas de dépendances |
| 10K-1M docs, déjà sur Postgres | pgvector | Intégration naturelle, performant |
| > 1M docs, multi-tenant | Qdrant, Weaviate, Pinecone | Vector stores dédiés, scalables |
| Logs opérations agents | PostgreSQL (table agent_logs) | Audit, dashboards, requêtes ad hoc |
9. Checklist intégration DB
- ✅ Credentials via vault uniquement — jamais dans le workspace Git, jamais en dur dans un script
- ✅ Utilisateur PostgreSQL dédié à l'agent — droits minimaux (SELECT/INSERT/UPDATE sur les tables nécessaires uniquement)
- ✅ Pool de connexions — ne pas ouvrir une nouvelle connexion par requête en production (utilisez pgBouncer ou un pool applicatif)
- ✅ Timeout sur les requêtes — toujours définir un statement_timeout, un agent ne doit pas bloquer indéfiniment
- ✅ Requêtes paramétrées uniquement — jamais de f-string dans un SELECT, risque d'injection SQL même depuis un agent
- ✅ Résultats écrits dans data/ — l'agent lit les résultats depuis un fichier, pas directement depuis la connexion DB
- ✅ Index sur les colonnes fréquentes — l'agent ne doit pas lancer de full scans sur des tables de 100K lignes
- ✅ Seuil de similarité RAG — toujours filtrer les résultats avec un score minimum (> 0.65–0.7), les résultats non pertinents sont pires que rien
- ✅ Réindexation planifiée, pas en temps réel — réindexer les embeddings en batch (nuit, weekend), pas à chaque écriture
- ✅ Tester la régression — après chaque modification du corpus, vérifier que les requêtes de référence retournent toujours les bons passages
10. Conclusion de la série OpenClaw
Ce dixième billet marque la fin de la série technique OpenClaw sur blog.botum.ca. En dix épisodes, BOTUM a documenté un déploiement réel — de l'installation initiale jusqu'à l'intégration base de données et la recherche sémantique.
Un récapitulatif de la trajectoire :
- B1-B2 — Le concept, l'installation, le premier agent opérationnel
- B3-B4 — Sécurité en production : auth, SSL, vault, gestion des secrets dans le contexte IA
- B5 — Réseau d'agents spécialisés : identités, rôles, communication inter-agents
- B6-B7 — Choix de LLM : comparatif honnête, DeepSeek et modèles locaux open-source
- B8-B9 — Automatisation avancée : crons, triggers, files de tâches, mémoire long terme
- B10 — Persistance structurée : PostgreSQL, RAG, recherche sémantique
La série suivante explorera les dimensions business et stratégiques : métriques ROI, architectures PME vs Enterprise, et déploiements edge. Ces articles paraîtront dans la section Insights de botum.ca.
🚀 Prêt à connecter votre infrastructure IA à vos données ?
Vous avez maintenant les 10 piliers d'un déploiement OpenClaw enterprise. Mais entre lire un guide et déployer en production, il y a l'architecture réelle, les décisions d'intégration, et les pièges qui ne sont dans aucune documentation.
Les équipes BOTUM accompagnent les organisations de l'audit technique jusqu'à la mise en production. Chaque projet est unique — le vôtre aussi.
Parler à un expert BOTUM →📄 Télécharger ce guide en PDF
Version complète de ce billet : PostgreSQL, RAG et recherche sémantique avec OpenClaw — format PDF optimisé pour lecture et partage.
Télécharger le PDF →Index complet — Série OpenClaw B1–B10
- B1 — OpenClaw : de l'assistant IA au réseau d'agents — retour terrain
- B2 — Installer OpenClaw : workspace, messagerie, premier agent opérationnel
- B3 — Sécuriser OpenClaw en production : auth, SSL, reverse proxy et vault
- B4 — Secrets et credentials dans le contexte IA — ne jamais exposer
- B5 — Configurer ses premiers agents : JARVIS, HERMÈS, CHRONOS
- B6 — OpenClaw vs ChatGPT vs Claude API — comparatif honnête
- B7 — OpenClaw + DeepSeek : LLM local, open-source et réduction des coûts API
- B8 — Automatiser les opérations : crons, triggers, files de tâches, escalades
- B9 — Mémoire et contexte : MEMORY.md, compactions et long-terme à l'échelle
- B10 — OpenClaw + bases de données : PostgreSQL, RAG et recherche sémantique ← vous êtes ici
🚀 Aller plus loin avec BOTUM
Ce guide couvre les bases. En production, chaque environnement a ses spécificités. Les équipes BOTUM accompagnent les organisations dans le déploiement, la configuration avancée et la sécurisation de leur infrastructure. Si vous avez un projet, parlons-en.
Discuter de votre projet →
