Haute disponibilité self-hosted : backups, snapshots et reprise
Stratégie backup complète pour infrastructure self-hosted : règle 3-2-1, snapshots Proxmox, backups Docker, rclone vers Backblaze B2 et tests de restauration.
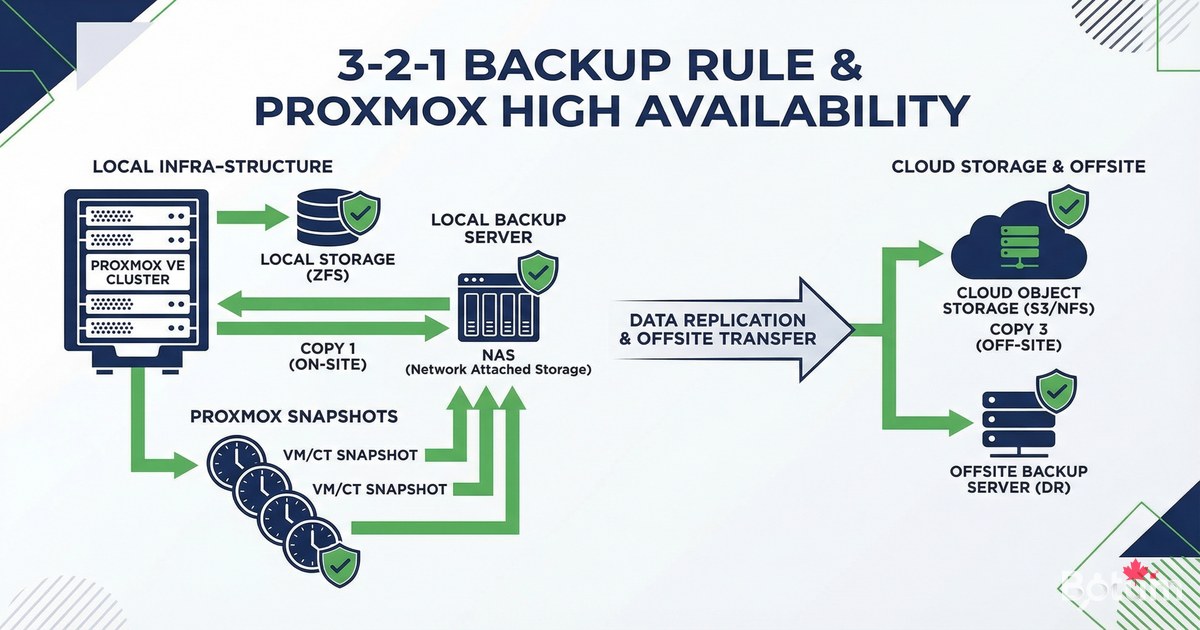
La meilleure infrastructure self-hosted est celle qui tient quand les choses tournent mal. Dans cet article final de la série, je vous montre la stratégie backup complète de BOTUM : règle 3-2-1, snapshots Proxmox, backups Docker, et surtout — les tests de restauration, l'étape que tout le monde oublie.
La règle 3-2-1 — Le fondement de toute stratégie backup
La règle 3-2-1 est le standard de l'industrie pour les sauvegardes. Simple et efficace :
- 3 copies de vos données (original + 2 sauvegardes)
- 2 supports différents (ex: SSD local + NAS)
- 1 copie hors site (cloud, autre bâtiment)
- La copie hors site protège contre incendie, vol, inondation
- Le test de restauration prouve que vos backups fonctionnent vraiment
Pour une infrastructure self-hosted typique : données actives (SSD serveur) + backup local (NAS ou second disque) + backup cloud (Backblaze B2, AWS S3, ou rclone vers n'importe quel cloud).
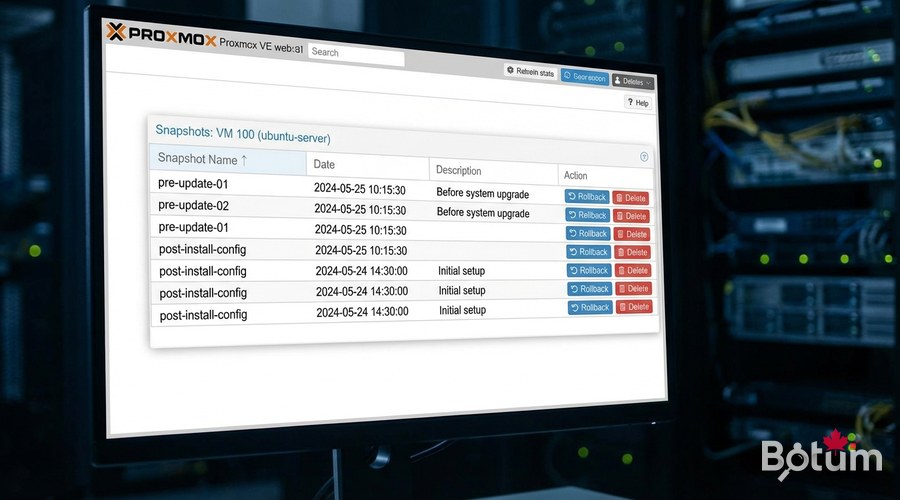
Snapshots Proxmox — Sauvegarde instantanée des VMs
Les snapshots Proxmox sauvegardent l'état complet d'une VM (disque + RAM optionnel) en quelques secondes. Idéal avant une mise à jour majeure ou un changement de configuration risqué.
# Créer un snapshot via CLI Proxmox :
qm snapshot <VMID> <nom-snapshot> --description "Description"
# Exemple :
qm snapshot 101 avant-upgrade-kernel --description "Avant kernel 6.8"
# Lister les snapshots :
qm listsnapshot 101
# Restaurer un snapshot (la VM doit être arrêtée) :
qm stop 101
qm rollback 101 avant-upgrade-kernel
qm start 101
# Supprimer un snapshot :
qm delsnapshot 101 avant-upgrade-kernel
# Snapshot programmatique (cron Proxmox) :
# Datacenter > Storage > Backup > Add
# Schedule: tous les jours à 2h00
# Mode: Snapshot ou Stop (plus cohérent)
# Retention: garder les 7 derniers backupsProxmox Backup Server (PBS) — Backups déduplicados
Proxmox Backup Server est l'outil de backup officiel de Proxmox. Il offre la déduplication, la compression et les backups incrémentaux — ce qui réduit drastiquement l'espace disque nécessaire.
# Installer PBS sur un serveur dédié (ou une VM) :
# 1. Télécharger l'ISO PBS depuis proxmox.com/downloads
# 2. Installer sur une machine séparée (recommandé)
# 3. Dans Proxmox VE > Datacenter > Storage > Add > Proxmox Backup Server
# Server: IP-de-votre-PBS
# Datastore: le nom du datastore PBS
# Fingerprint: (copier depuis PBS)
# Créer un job de backup dans Proxmox VE :
# Datacenter > Backup > Add
# Storage: votre-PBS
# Schedule: tous les jours à 2:00
# Selection: inclure toutes les VMs
# Mode: Snapshot (sans arrêt) ou Suspend (bref arrêt)
# Retention: 7 daily, 4 weekly, 3 monthly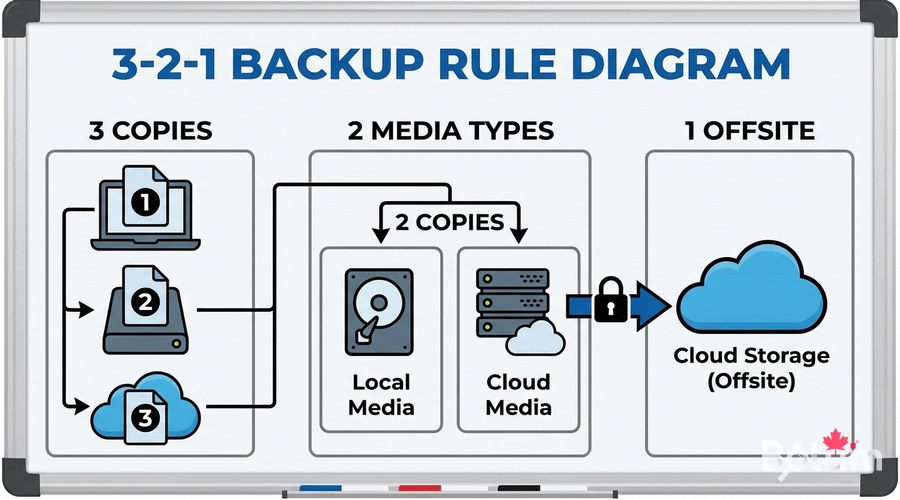
Backup des volumes Docker
Pour les services Docker qui tournent hors Proxmox (ou sur un VPS), voici la stratégie de backup des volumes :
#!/bin/bash
# Script complet de backup Docker vers NAS + Cloud
BACKUP_LOCAL="/mnt/nas/backups/docker/$(date +%Y-%m-%d)"
BACKUP_LOG="/var/log/docker-backup.log"
mkdir -p "$BACKUP_LOCAL"
# Fonction de backup d'un service Docker
backup_service() {
local name="$1"
local path="$2"
echo "$(date): Backup $name" | tee -a "$BACKUP_LOG"
tar czf "${BACKUP_LOCAL}/${name}-$(date +%Y%m%d_%H%M%S).tar.gz" "$path" 2>> "$BACKUP_LOG" && echo "OK: $name" | tee -a "$BACKUP_LOG" || echo "ERREUR: $name" | tee -a "$BACKUP_LOG"
}
# Ghost Blog (arrêt non nécessaire pour SQLite)
backup_service "ghost" "/mnt/docker-data/ghost-blog/content"
# Vaultwarden (arrêt bref recommandé)
docker stop vaultwarden 2>/dev/null
backup_service "vaultwarden" "$HOME/docker/vaultwarden/data"
docker start vaultwarden 2>/dev/null
# Uptime Kuma
backup_service "uptime-kuma" "$HOME/docker/uptime-kuma/data"
# Zoraxy
backup_service "zoraxy" "$HOME/docker/zoraxy/data"
echo "$(date): Backup local terminé" | tee -a "$BACKUP_LOG"
# Synchronisation vers cloud avec rclone
rclone sync "$BACKUP_LOCAL" "b2:mon-bucket-backups/docker/$(date +%Y-%m-%d)/" --log-file="$BACKUP_LOG" && echo "$(date): Sync cloud OK" | tee -a "$BACKUP_LOG"
# Nettoyage des backups de plus de 30 jours
find /mnt/nas/backups/docker -maxdepth 1 -type d -mtime +30 -exec rm -rf {} +Installer et configurer rclone pour Backblaze B2
# Installer rclone :
curl https://rclone.org/install.sh | sudo bash
# Configurer Backblaze B2 :
rclone config
# > New remote (n)
# > Name: b2
# > Provider: Backblaze B2
# > account: votre-application-key-id
# > key: votre-application-key
# > Save
# Créer un bucket B2 :
rclone mkdir b2:mon-bucket-backups
# Test de synchronisation :
rclone sync /backup/test/ b2:mon-bucket-backups/test/ --progress
# Vérifier le contenu du bucket :
rclone ls b2:mon-bucket-backups/
# Coûts Backblaze B2 : ~0.006$/Go/mois (très économique)Test de restauration — L'étape critique
Un backup non testé n'est pas un backup — c'est une espérance. Testez régulièrement vos restaurations sur une VM de test :
# Test de restauration Proxmox (VM de test) :
# 1. Dans Proxmox : Datacenter > Backup > sélectionner un backup > Restore
# 2. Choisir une VM ID différente (ex: 999 pour les tests)
# 3. Restaurer sur un stockage de test
# 4. Démarrer la VM de test
# 5. Vérifier que les services sont opérationnels
# Test de restauration Docker (sur VM séparée) :
# 1. Créer une nouvelle VM Ubuntu de test
# 2. Installer Docker
# 3. Copier le backup depuis le NAS ou cloud
# Restaurer Ghost Blog :
mkdir -p /test/ghost-blog/content
tar xzf /backup/ghost-20260312.tar.gz -C /test/ghost-blog/content/
# Démarrer Ghost sur le port 2368 de la VM de test
# Vérifier que le blog est lisible
# Restaurer Vaultwarden :
mkdir -p /test/vaultwarden/data
cp /backup/vaultwarden-20260312.db /test/vaultwarden/data/db.sqlite3
# Démarrer Vaultwarden et vérifier l'accès
echo "Test de restauration réussi !" 
Monitoring de l'intégrité des backups
#!/bin/bash
# /usr/local/bin/check-backups.sh
# Vérifie que les backups sont récents et intact
BACKUP_DIR="/mnt/nas/backups/docker"
MAX_AGE_HOURS=25 # Alerte si pas de backup depuis 25h
TELEGRAM_TOKEN="VOTRE_TOKEN"
TELEGRAM_CHAT="VOTRE_CHAT_ID"
alert() {
curl -s -X POST "https://api.telegram.org/bot${TELEGRAM_TOKEN}/sendMessage" -d chat_id="${TELEGRAM_CHAT}" -d text="[BACKUP] $1" > /dev/null
}
# Vérifier l'existence du dernier backup
LAST_BACKUP=$(find "$BACKUP_DIR" -maxdepth 1 -type d -name "20*" | sort | tail -1)
if [[ -z "$LAST_BACKUP" ]]; then
alert "ERREUR: Aucun backup trouvé dans $BACKUP_DIR"
exit 1
fi
# Vérifier l'âge du dernier backup
BACKUP_AGE=$(( ($(date +%s) - $(stat -c %Y "$LAST_BACKUP")) / 3600 ))
if (( BACKUP_AGE > MAX_AGE_HOURS )); then
alert "ALERTE: Dernier backup a ${BACKUP_AGE}h (seuil: ${MAX_AGE_HOURS}h)"
fi
# Vérifier l'intégrité des archives tar
for f in "$LAST_BACKUP"/*.tar.gz; do
if ! tar tzf "$f" > /dev/null 2>&1; then
alert "ERREUR: Archive corrompue: $f"
fi
done
echo "Vérification backups OK - Dernier backup: $LAST_BACKUP (${BACKUP_AGE}h)" Plan de reprise d'activité (PRA)
Un bon PRA définit exactement quoi faire en cas de sinistre, dans quel ordre, et combien de temps ça prend :
- RTO (Recovery Time Objective) : temps max acceptable pour restaurer le service
- RPO (Recovery Point Objective) : perte de données max acceptable (ex: 24h si backup quotidien)
- Documenter chaque service : IP, ports, dépendances, commandes de restauration
- Tenir un runbook à jour : liste ordonnée des étapes de restauration
- Tester le PRA au moins une fois par an (exercice de sinistre)
Haute disponibilité avec Proxmox Cluster
# Pour un niveau HA (haute disponibilité) avec Proxmox :
# Minimum : 3 nœuds Proxmox + stockage partagé (Ceph ou NFS)
# Créer un cluster Proxmox (sur le nœud principal) :
pvecm create mon-cluster
# Rejoindre le cluster (sur les autres nœuds) :
pvecm add IP-DU-NOEUD-PRINCIPAL
# Vérifier le statut du cluster :
pvecm status
pvecm nodes
# Activer HA pour une VM :
# Datacenter > HA > Add
# VM ID: 101
# Group: (optionnel)
# Max restart: 3
# Max relocate: 3
# En cas de panne d'un nœud, les VMs HA migrent
# automatiquement vers un nœud disponible.Conclusion de la série
Félicitations ! Vous avez maintenant une infrastructure self-hosted complète et professionnelle : virtualisation Proxmox, conteneurisation Docker, reverse proxy SSL Zoraxy, gestion de mots de passe Vaultwarden, monitoring Uptime Kuma, automatisation et backups.
Cette série vous a montré exactement comment l'infrastructure BOTUM est construite. L'auto-hébergement n'est plus réservé aux experts — avec ces outils, n'importe qui peut gérer son infrastructure comme un professionnel. Bonne chance dans votre aventure self-hosted !
Téléchargez ce guide en PDF pour le consulter hors ligne.
⬇ Télécharger le guide (PDF)🚀 Aller plus loin avec BOTUM
Ce guide couvre les bases. En production, chaque environnement a ses spécificités. Les équipes BOTUM accompagnent les organisations dans le déploiement, la configuration avancée et la sécurisation de leur infrastructure. Si vous avez un projet, parlons-en.
Discuter de votre projet →
