FinOps : maîtriser les coûts cloud pour les PME canadiennes
Votre facture cloud a triplé le premier mois ? Découvrez comment les PME canadiennes appliquent le FinOps pour réduire leurs coûts cloud de 30 à 47% — outils, leviers concrets et cas réel BOTUM.
La scène se répète dans presque toutes les PME qui migrent vers le cloud. La décision est prise, l'enthousiasme est là : "On va enfin sauver de l'argent sur notre infrastructure !" Puis la première facture AWS, Azure ou GCP tombe. Elle est trois fois plus élevée que prévu. Le silence dans la salle de réunion dit tout.
Ce n'est pas un bug — c'est la nature du cloud. Le modèle à la consommation est puissant, mais il est impitoyable si vous ne le gérez pas activement. La bonne nouvelle : une discipline existe pour ça. Elle s'appelle le FinOps, et elle est à la portée de toute PME, même sans équipe dédiée.
C'est quoi le FinOps — vraiment ?
FinOps n'est pas un outil. Ce n'est pas non plus une simple ligne de budget. C'est une pratique culturelle qui réunit les équipes Finance, DevOps et Produit autour d'un objectif commun : aligner chaque dollar dépensé en cloud avec la valeur business qu'il génère.
La FinOps Foundation, qui en définit le cadre standard, le résume ainsi : "FinOps is an evolving cloud financial management discipline and cultural practice that enables organizations to get maximum business value by helping engineering, finance, technology and business teams to collaborate on data-driven spending decisions."
Concrètement, ça veut dire :
- Les ingénieurs savent ce que leur code coûte en production
- Le département finance comprend pourquoi une spike de coût est normale lors d'un lancement
- Les décisions de capacité sont basées sur des données réelles, pas des estimations
- Tout le monde partage la responsabilité du spend — pas seulement le CFO qui reçoit la facture
Pour une PME de 15 à 200 employés, ça peut paraître ambitieux. En réalité, les principes s'appliquent avec un seul "champion FinOps" — un DevOps senior ou un CTO qui y consacre 20% de son temps.
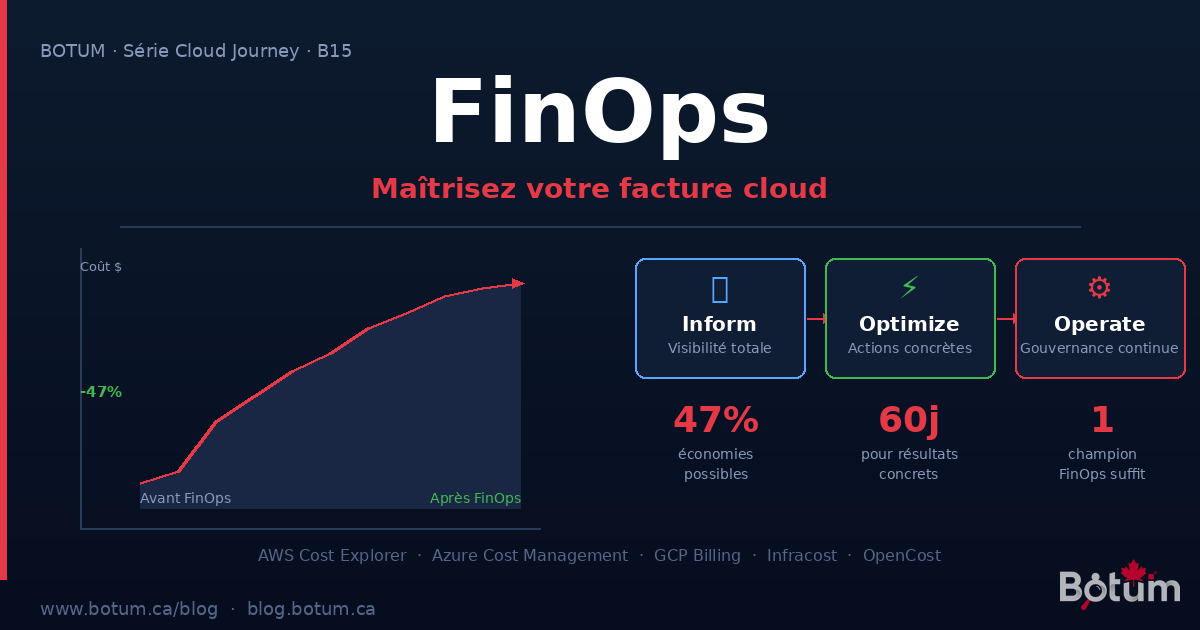
Les 3 phases du cycle FinOps
Le framework FinOps définit un cycle itératif en trois phases. Vous n'en sortez jamais — vous tournez en continu :
Phase 1 — Inform : la visibilité totale
Avant d'optimiser quoi que ce soit, vous devez voir où va l'argent. Ça semble évident ; ça ne l'est pas. La plupart des entreprises reçoivent leur facture cloud comme un bloc opaque.
- Activer le tagging : chaque ressource porte un tag
project,environment,team,owner - Configurer les cost allocation reports (AWS Cost Explorer, Azure Cost Analysis)
- Créer des budgets par équipe / projet / environnement
- Mettre en place des alertes à 50%, 80%, 100% du budget mensuel
Objectif de cette phase : répondre à "qui dépense quoi, pour quoi ?" en moins de 5 minutes.
Phase 2 — Optimize : les actions concrètes
Une fois la visibilité établie, vous identifiez les opportunités d'économies et les implémentez. C'est la phase la plus tangible — c'est là que la facture baisse.
- Rightsizing des instances surdimensionnées
- Achat de Reserved Instances ou Savings Plans pour les charges stables
- Migration des workloads batch vers les Spot/Preemptible Instances
- Suppression des ressources orphelines (IPs, snapshots, load balancers vides)
- Implémentation de l'auto-scaling agressif pour dev/staging
Phase 3 — Operate : la gouvernance continue
L'optimisation n'est pas un projet avec une date de fin. C'est un processus permanent. Cette phase établit les mécanismes qui maintiennent les économies dans le temps :
- Revues mensuelles des coûts (30 minutes, toute l'équipe technique)
- Politiques d'auto-shutdown pour les environnements de développement
- Approbation requise pour les instances > certaine taille
- Drift alerts quand le spend dépasse une baseline établie
Les outils FinOps — cloud natifs et open source
Chaque cloud provider offre ses propres outils de visibilité financière. Voici ce qui est utilisable immédiatement :
AWS Cost Explorer : l'outil le plus complet du marché. Visualisation par service, par tag, par région, par type d'usage. La vue "Rightsizing Recommendations" identifie automatiquement vos instances surdimensionnées avec une estimation d'économies. Coût : 0,01 USD par requête API — négligeable.
Azure Cost Management + Billing : intégré au portail Azure. Permet de créer des budgets par Resource Group, par tag, par abonnement. Les alertes sont configurables par email et webhook. L'intégration avec Azure Advisor fournit des recommandations de rightsizing directement dans la console.
GCP Billing Reports : tableaux de bord BigQuery natifs avec export automatique vers un dataset. Permet des requêtes SQL custom sur votre historique de coûts — particulièrement puissant pour identifier les patterns d'utilisation sur 12 mois.
Infracost : outil open source qui s'intègre dans votre pipeline CI/CD. À chaque Pull Request Terraform, il calcule le delta de coût de vos changements d'infrastructure et le poste en commentaire sur la PR. Un ingénieur sait exactement ce que son changement va coûter avant de merger.
OpenCost : outil CNCF open source pour les environnements Kubernetes. Alloue les coûts par namespace, deployment, label. Indispensable si vous utilisez Kubernetes et voulez savoir ce que chaque microservice coûte réellement.
Les 5 leviers d'optimisation
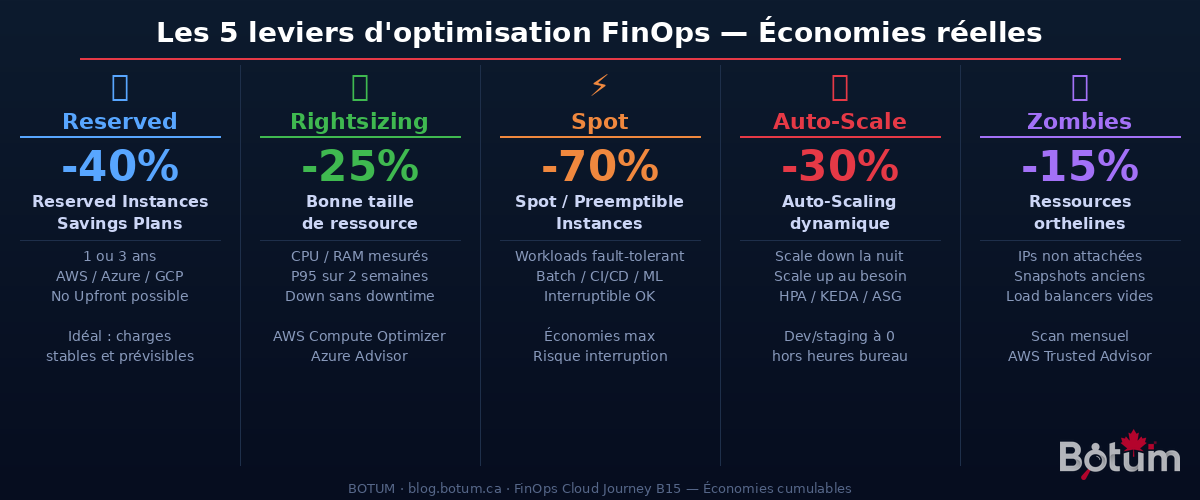
1. Reserved Instances et Savings Plans (-30% à -40%)
Si vous avez des charges stables et prévisibles — un serveur de base de données, un cluster applicatif en production — vous laissez de l'argent sur la table en payant l'On-Demand à la minute.
Les Reserved Instances (AWS) ou Savings Plans offrent jusqu'à 40% de réduction en contrepartie d'un engagement de 1 ou 3 ans. La formule "No Upfront" ne demande aucun paiement initial — juste un engagement de durée. Sur AWS, un m5.xlarge On-Demand coûte ~0,192 USD/h ; en Reserved 1 an No Upfront, ~0,118 USD/h. Sur 8 760 heures annuelles : 645 USD d'économies par instance.
2. Rightsizing (-20% à -30%)
La plupart des instances cloud sont surdimensionnées. Provisionné en rush pour un lancement, personne n'a revu la taille depuis. Une analyse de 14 jours de métriques CPU/RAM révèle souvent que l'instance roule à 15% de CPU en moyenne.
AWS Compute Optimizer et Azure Advisor font ce travail automatiquement. La règle : mesurez le P95 (95e percentile) de l'utilisation, pas le pic absolu. Si votre m5.2xlarge dépasse rarement 40% de CPU au P95, un m5.xlarge suffit — à moitié prix.
3. Spot et Preemptible Instances (-60% à -75%)
Les instances Spot (AWS), Spot VMs (Azure) ou Preemptible (GCP) utilisent la capacité excédentaire des datacenters. Moins chères de 60 à 75%, elles peuvent être récupérées par le provider avec un préavis de 2 minutes.
Adaptées aux workloads tolérants à l'interruption : pipelines CI/CD, jobs de data processing, entraînement ML, rendering vidéo. Votre pipeline GitHub Actions qui tourne 4 heures par jour peut coûter 75% moins cher sur des workers Spot.
4. Auto-Scaling dynamique (-25% à -35%)
L'auto-scaling n'est pas réservé aux pics de trafic — c'est aussi l'outil principal pour réduire les coûts hors des heures d'utilisation.
Politique concrète : vos environnements de développement et staging passent à zéro instance la nuit (22h-8h) et les weekends. Pour une entreprise avec 5 environnements de dev/staging sur AWS, ça représente 65% d'économies sur ces instances (16h actif sur 24h = ~33% du temps). Sur Kubernetes, le Cluster Autoscaler + KEDA permettent de scaler à zéro les namespaces non utilisés.
5. Suppression des ressources orphelines (-10% à -20%)
Les "zombies cloud" s'accumulent silencieusement. Un développeur supprime une VM mais oublie son IP élastique (0,005 USD/h pour rien). Des snapshots EBS s'accumulent pendant 2 ans. Un load balancer créé pour un test il y a 8 mois tourne toujours.
Un scan mensuel avec AWS Trusted Advisor, Azure Advisor ou l'outil open source cloud-nuke révèle systématiquement entre 5 et 15% de ressources inutilisées dans tout compte cloud actif depuis plus de 6 mois.
Tableau comparatif : Reserved vs On-Demand vs Spot
| Type | Économies vs On-Demand | Engagement | Cas d'usage | Risque |
|---|---|---|---|---|
| On-Demand | Référence (0%) | Aucun | Charges variables, nouveaux projets | Coût max — à éviter en production stable |
| Reserved 1 an | -30% à -37% | 1 an (flexible) | Production, DB, charges stables | Faible — sous-utilisation si over-provisionné |
| Reserved 3 ans | -40% à -60% | 3 ans (ferme) | Infrastructure cœur très stable | Moyen — rigidité sur 3 ans |
| Savings Plans | -25% à -40% | 1 ou 3 ans | Flexible (any instance family/region) | Faible — plus flexible que RI |
| Spot/Preemptible | -60% à -75% | Aucun | Batch, CI/CD, ML, rendering | Interruption possible (2 min préavis) |
Gouvernance FinOps pour PME
La stratégie de tagging est le fondement de tout. Sans tags cohérents, impossible d'allouer les coûts. La taxonomy minimale recommandée :
# Tags obligatoires sur toutes les ressources
Project = "crm-v2" # Nom du projet ou produit
Environment = "production" # dev / staging / production
Team = "backend" # Équipe responsable
Owner = "marie.tremblay" # Responsable individuel
CostCenter = "IT-PROD-001" # Centre de coût comptableImposez ces tags via une Policy Azure (Azure Policy "Deny" sur les ressources sans tags requis) ou une SCP AWS (Service Control Policy). Aucune ressource ne peut être créée sans tags — point.
Les budget alerts sont non-négociables. Configurez au minimum :
- Alerte à 50% du budget mensuel → information
- Alerte à 80% du budget mensuel → investigation requise
- Alerte à 100% → action immédiate, notification Slack + email direction
Le champion FinOps PME : vous n'avez pas besoin d'une équipe dédiée. Un seul DevOps senior qui consacre 20% de son temps au FinOps — soit environ 8 heures par semaine — est suffisant pour gérer un compte cloud jusqu'à 50 000 CAD/mois. Ses responsabilités :
- Revue hebdomadaire du spend (30 min)
- Revue mensuelle avec le management (1h)
- Approbation des nouvelles ressources importantes
- Audit trimestriel des Reserved Instances (renouveler ? ajuster ?)
Les erreurs qui coûtent cher
❌ Payer l'On-Demand par défaut
La pire erreur. Une startup qui a une production stable depuis 6 mois sur des instances On-Demand laisse facilement 30 à 40% de sa facture sur la table. La règle : dès qu'une charge tourne plus de 3 mois en production, évaluez les Reserved Instances ou Savings Plans.
❌ Les environnements de dev actifs 24/7
Un environnement de développement qui tourne la nuit et le weekend ne fait rien — il brûle de l'argent. Implémentez des Instance Scheduler (AWS) ou Azure Auto-shutdown sur tous les environnements non-production. Économies typiques : 60 à 70% du coût de ces instances.
❌ Les snapshots EBS/disques qui s'accumulent
Un snapshot EBS coûte 0,05 USD/Go/mois. Une base de données de 500 Go avec une rétention non gérée accumule 50 snapshots en 2 ans = 1 250 USD/mois pour des sauvegardes dont personne ne sait si elles sont encore utiles. Définissez une politique de rétention : 7 jours daily, 4 semaines weekly, 12 mois monthly — et supprimez automatiquement le reste.
❌ Les egress fees ignorés
Le transfert de données sortant du cloud est facturé — et rarement anticipé. AWS facture de 0,08 à 0,09 USD/Go en sortie vers internet. Pour une application avec beaucoup de trafic sortant, ça peut représenter 15 à 25% de la facture totale. Solutions : utiliser CloudFront (AWS) ou Azure CDN pour mettre en cache les assets, activer la compression (gzip/brotli), et évaluer les AWS Outposts ou Azure Stack pour les charges avec énorme volume de données sortantes.
Cas concret BOTUM : -47% en 60 jours
Contexte : PME de services B2B, 28 employés, stack AWS (EC2, RDS, S3, ALB). Facture mensuelle initiale : 8 400 USD/mois. Le CTO nous contacte après avoir reçu une alerte sur une facture anormalement élevée.
Audit initial (semaine 1-2) :
- 6 instances EC2
m5.xlargeen production tournant à 8-15% de CPU en moyenne - Aucune Reserved Instance — tout en On-Demand depuis 14 mois
- 3 environnements de dev/staging actifs 24/7 (weekends inclus)
- 847 snapshots EBS accumulés sur 2 ans, représentant 12 TB
- 4 Elastic IPs non attachées, 2 load balancers vides, 1 NAT Gateway inutilisé
- Aucun tagging cohérent — impossible d'allouer les coûts par projet
Plan d'action et exécution (semaine 3-8) :
- Rightsizing EC2 : 6 ×
m5.xlarge→ 6 ×t3.largeaprès analyse P95 sur 14 jours. Économie : -1 200 USD/mois - Reserved Instances : 6 instances production + 2 RDS achetées en RI 1 an No Upfront. Économie : -1 650 USD/mois
- Suppression des zombies : 843 snapshots supprimés (politiques de rétention configurées), IPs et LBs orphelins retirés. Économie : -890 USD/mois
- Auto-shutdown dev/staging : Instance Scheduler AWS sur 3 environnements, arrêt 22h-8h + weekends. Économie : -620 USD/mois
- Tagging complet : politique Azure-style implémentée via SCP. Nouveau baseline de visibilité établi.
Résultat à 60 jours : 8 400 USD → 4 452 USD/mois. Économie : 3 948 USD/mois (-47%). Soit près de 47 400 USD sur 12 mois — pour un investissement de 3 semaines de travail d'audit et implémentation.
Le champion FinOps désigné maintient maintenant ces économies avec une revue hebdomadaire de 30 minutes. La facture est restée stable à ±5% depuis.
Par où commencer dès cette semaine
Si vous n'avez jamais fait de FinOps, voici les 3 actions à impact immédiat :
- Activez les Cost Explorer recommandations de rightsizing sur AWS (ou Azure Advisor). Vous aurez une liste d'économies potentielles en 48h.
- Inventoriez vos ressources orphelines : IPs non attachées, snapshots > 90 jours, load balancers sans cibles. Supprimez. Économie immédiate.
- Configurez un budget alert à 80% de votre spend mensuel actuel. Vous ne serez plus jamais surpris par une facture.
Le reste — Reserved Instances, auto-scaling, gouvernance complète — se construit par itérations. Mais ces 3 actions, vous pouvez les faire cette semaine, sans risk, sans architecture review.
Téléchargez ce guide FinOps en PDF.
⬇ Télécharger le guide (PDF)🚀 Aller plus loin avec BOTUM
Audit FinOps, optimisation cloud, réduction de facture — les équipes BOTUM accompagnent les PME canadiennes.
Discuter de votre projet →
